Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive for / cplusplus /
Does const mean thread-safe?
Tuesday, 14 March 2017
There was a discussion recently on
the cpplang slack about whether const
meant thread-safe.
As with everything in life, it depends. In some ways, yes it does. In others, it does not. Read on for the details.
What do we mean by "thread-safe"?
If someone says something is "thread-safe", then it is important to define what that means. Here is an incomplete list of some things people might mean when they say something is "thread safe".
- Calling
foo(x)on one thread andfoo(y)on a second thread concurrently is OK. - Calling
foo(x_i)on any number of threads concurrently is OK, provided eachx_iis different. - Calling
foo(x)on a specific number of threads concurrently is OK. - Calling
foo(x)on any number of threads concurrently is OK. - Calling
foo(x)on one thread andbar(x)on another thread concurrently is OK. - Calling
foo(x)on one thread andbar(x)on any number of threads concurrently is OK.
Which one we mean in a given circumstance is important. For example, a concurrent queue might be a Single-Producer, Single-Consumer queue (SPSC), in which case it is safe for one thread to push a value while another pops a value, but if two threads try and push values then things go wrong. Alternatively, it might be a Multi-Producer, Single-Consumer queue (MPSC), which allows multiple threads to push values, but only one to pop values. Both of these are "thread safe", but the meaning is subtly different.
Before we look at what sort of thread safety we're after, let's just define what it means to be "OK".
Data races
At the basic level, when we say an operation is "OK" from a thread-safety point of view, we mean it has defined behaviour, and there are no data races, since data races lead to undefined behaviour.
From the C++ Standard perspective, a data race is where there are 2 operations that access the same memory location, such that neither happens-before the other, at least one of them modifies that memory location, and at least one of them is not an atomic operation.
An operation is thus "thread safe" with respect to the set of threads we wish to perform the operation concurrently if:
- none of the threads modify a memory location accessed by any of the other threads, or
- all accesses performed by the threads to memory locations which are modified by one or more of the threads are atomic, or
- the threads use suitable synchronization to ensure that there are happens-before operations between all modifications, and any other accesses to the modified memory locations.
So: what sort of thread-safety are we looking for from const objects, and why?
Do as ints do
A good rule of thumb for choosing behaviour for a class in C++ is "do as
ints do".
With regard to thread safety, ints are simple:
- Any number of threads may read a given
intconcurrently - If any thread modifies a given
int, no other threads may access thatintfor reading or writing concurrently.
This follows naturally from the definition of a data race, since ints cannot
do anything special to provide synchronization or atomic operations.
If you have an int, and more than one thread that wants to access it, if any
of those threads wants to modify it then you need external
synchronization. Typically you'll use a mutex for the external synchronization,
but other mechanisms can work too.
If your int is const, (or you have const int& that references it, or
const int* that points to it) then you can't modify it.
What does that mean for your class? In a well-designed class, the const member
functions do not modify the state of the object. It is "logically" immutable
when accessed exclusively through const member functions. On the other hand,
if you use a non-const member function then you are potentially modifying the
state of the object. So far, so good: this is what ints do with regard to
reading and modifying.
To do what ints do with respect to thread safety, we need to ensure that it is
OK to call any const member functions concurrently on any number of
threads. For many classes this is trivially achieved: if you don't modify the
internal representation of the object in any way, you're home dry.
Consider an employee class that stores basic information about an employee,
such as their name, employee ID and so forth. The natural implementation of
const member functions will just read the members, perform some simple
manipulation on the values, and return. Nothing is modified.
class employee{
std::string first_name;
std::string last_name;
// other data
public:
std::string get_full_name() const{
return last_name + ", " + first_name;
}
// other member functions
}Provided that reading from a const std::string and appending it to another
string is OK, employee::get_full_name is OK to be called from any number of
threads concurrently.
You only have to do something special to "do as ints do" if you modify the
internal state in your const member function, e.g. to keep a tally of calls,
or cache calculation values, or similar things which modify the internal state
without modifying the externally-visible state. Of course, you would also need
to add some synchronization if you were modifying externally-visible state in
your const member function, but we've already decided that's not a good plan.
In employee::get_full_name, we're relying on the thread-safety of
std::string to get us through. Is that OK? Can we rely on that?
Thread-safety in the C++ Standard Library
The C++ Standard Library itself sticks to the "do as ints do" rule. This is
spelled out in the section on Data race
avoidance
(res.on.data.races). Specifically,
A C++ standard library function shall not directly or indirectly modify objects accessible by threads other than the current thread unless the objects are accessed directly or indirectly via the function's non-
constarguments, includingthis.
and
Implementations may share their own internal objects between threads if the objects are not visible to users and are protected against data races.
This means that if you have a const std::string& referencing an object, then
any calls to member functions on it must not modify the object, and any
shared internal state must be protected against data races. The same applies if
it is passed to any other function in the C++ Standard Library.
However, if you have a std::string& referencing the same object, then you must
ensure that all accesses to that object must be synchronized externally,
otherwise you may trigger a data race.
Our employee::get_full_name function is thus as thread-safe as an int:
concurrent reads are OK, but any modifications will require external
synchronization for all concurrent accesses.
There are two little words in the first paragraph quoted above which have a surprising consequence: "or indirectly".
Indirect Accesses
If you have two const std::vector<X>s, vx and vy, then calling standard
library functions on those objects must not modify any objects accessible by
other threads, otherwise we've violated the requirements from the "data race
avoidance" section quoted above, since those objects would be "indirectly"
modified by the function.
This means that any operations on the X objects within those containers that
are performed by the operations we do on the vectors must also refrain from
modifying any objects accessible by other threads. For example, the expression
vx==vy compares each of the elements in turn. These comparisons must thus not
modify any objects accessible by other threads. Likewise,
std::for_each(vx.begin(),vx.end(),foo) must not modify any objects accessible
by other threads.
This pretty much boils down to a requirement that if you use your class with the
C++ Standard Library, then const operations on your class must be safe if
called from multiple threads. There is no such requirement for non-const
operations, or combinations of const and non-const operations.
You may of course decide that your class is going to allow concurrent
modifications (even if that is by using a mutex to restrict accesses
internally), but that is up to you. A class designed for concurrent access, such
as a concurrent queue, will need to have the internal synchronization; a value
class such as our employee is unlikely to need it.
Summary
Do as ints do: concurrent calls to const member functions on your class must
be OK, but you are not required to ensure thread-safety if there are also
concurrent calls to non-const member functions.
The C++ Standard Library sticks to this rule itself, and requires it of your
code. In most cases, it's trivial to ensure; it's only classes with complex
const member functions that modify internal state that may need
synchronization added.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, const, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Generating Sequences
Monday, 27 February 2017
I was having a discussion with my son over breakfast about C++ and Python, and
he asked me if C++ had anything equivalent to Python's range() function for
generating a sequence of integers. I had to tell him that no, the C++ standard
library didn't supply such a function, but there were algorithms for generating
sequences (std::generate and std::generate_n) into an existing container,
and you could write something that would provide a "virtual" container that
would supply a sequence as you iterated over it with range-for.
He was happy with that, but I felt the urge to write such a container, and blog
about it. There are existing implementations available
(e.g. boost::counting_range),
but hopefully people will find this instructive, if not useful.
Iterating over a "virtual" container
Our initial goal is to be able write
for(int x: range(10))
std::cout<<x<<std::endl;and have it print out the numbers 0 to 9. This requires that our new range
function returns something we can use with range-for — something for
which we can call begin and end to get iterators.
class numeric_range{
public:
class iterator;
iterator begin();
iterator end();
};
numeric_range range(int count);Our container is virtual, so we don't have real values we can refer to. This
means our iterators must be input iterators — forward iterators need
real objects to refer to. That's OK though; we're designing this for use with
range-for, which only does one pass anyway.
Input Iterator requirements
All iterators have 5 associated types. They can either be provided as member
types/typedefs, or by specializing std::iterator_traits<>. If you provide
them as part of your iterator class, then the std::iterator_traits<>
primary template works fine, so we'll do that. The types are:
iterator_category
The tag type for the iterator category: for input iterators it's std::input_iterator_tag.
value_type
This is the type of the element in the sequence. For an integer sequence, it
would be int, but we'll want to allow sequences of other types, such as
unsigned, double, or even a custom class.
reference
The result of operator* on an iterator. For forward iterators it has to be an
lvalue reference, but for our input iterator it can be anything convertible to
value_type. For simplicity, we'll make it the same as value_type.
pointer
The return type of operator-> on an iterator. value_type* works for us, and
is the simplest option.
difference_type
The type used to represent the difference between two iterators. For input
iterators, this is irrelevant, as they provide a one-pass abstraction with no
exposed size. We can therefore use void.
The types aren't the only requirements on input iterators: we also have to meet the requirements on valid expressions.
Input Iterator expression requirements
Input iterators can be valid or invalid. If an iterator is invalid (e.g. because it was invalidated by some operation), then doing anything to it except assigning to it or destroying it is undefined behaviour, so we don't have to worry about that. All requirements below apply only to valid iterators.
Valid iterators can either refer to an element of a sequence, in which case they are dereferencable, or they can be past-the-end iterators, which are not dereferencable.
Comparisons
For iterators a and b, a==b is only a valid expression if a and b
refer to the same sequence. If they do refer to the same sequence, a==b is
true if and only if both a and b are past-the-end iterators, or both a
and b are dereferencable iterators that refer to the same element in the
sequence.
a!=b returns !(a==b), so is again only applicable if a and b are from
the same sequence.
Incrementing
Only dereferencable iterators can be incremented.
If a is dereferencable, ++a must move a to the next value in the sequence,
or make a a past-the-end iterator. Incrementing an iterator a may invalidate
all copies of a: input iteration is single-pass, so you cannot use iterators
to an element after you've incremented any iterator that referenced that
element. ++a returns a reference to a.
(void)a++ is equivalent to (void)++a. The return type is unspecified, and
not relevant to the increment.
Dereferencing
For a dereferencable iterator a, *a must return the reference type for
that iterator, which must be convertible to the value_type. Dereferencing the
same iterator multiple times without modifying the iterator must return an
equivalent value each time. If a and b are iterators such that a==b is
true, *a and *b must be return equivalent values.
a->m must be equivalent to (*a).m.
*a++ must return a value convertible to the value_type of our iterator, and
is equivalent to calling following the function:
iterator::value_type increment_and_dereference(iterator& a) {
iterator::value_type temp(*a);
++a;
return temp;
}This is why the return type for a++ is unspecified: for some iterators it will
need to be a special type that can generate the required value on dereferencing;
for others it can be a reference to a real value_type object.
Basic implementation
Our initial implementation can be really simple. We essentially just need a current value, and a final value. Our dereferencable iterators can then just hold a pointer to the range object, and past-the-end iterators can hold a null pointer. Iterators are thus equal if they are from the same range. Comparing invalidated iterators, or iterators from the wrong range is undefined behaviour, so that's OK.
class numeric_range{
int current;
int final;
public:
numeric_range(int final_):current(0),final(final_){}
iterator begin(){ return iterator(this); }
iterator end() { return iterator(nullptr); }
class iterator{
numeric_range* range;
public:
using value_type = T;
using reference = T;
using iterator_category=std::input_iterator_tag;
using pointer = T*;
using difference_type = void;
iterator(numeric_range* range_):range(range_){}
int operator*() const{ return range->current; }
int* operator->() const{ return &range->current;}
iterator& operator++(){ // preincrement
++range->current;
if(range->current==range->final)
range=nullptr;
return *this;
}
??? operator++(int); // postincrement
friend bool operator==(iterator const& lhs,iterator const& rhs){
return lhs.range==rhs.range;
}
friend bool operator!=(iterator const& lhs,iterator const& rhs){
return !(lhs==rhs);
}
};
};
numeric_range range(int max){
return numeric_range(max);
}Note that I've left out the definition of the iterator postincrement operator. That's because it warrants a bit more discussion.
Remember the spec for *a++: equivalent to calling
iterator::value_type increment_and_dereference(iterator& a) {
iterator::value_type temp(*a);
++a;
return temp;
}Since this is a combination of two operators, we can't do it directly: instead, our postincrement operator has to return a special type to hold the temporary value. Our postincrement operator thus looks like this:
class numeric_range::iterator{
class postinc_return{
int value;
public:
postinc_return(int value_): value(value_){}
int operator*(){ return value; }
};
public:
postinc_return operator++(int){
postinc_return temp(range->current);
++*this;
return temp;
}
};That's enough for our initial requirement:
int main(){
for(int x: range(10)){
std::cout<<x<<",";
}
std::cout<<std::endl;
}will now print 0 to 9.
More complete implementation
The Python range function provides more options than just this, though: you
can also specify start and end values, or start, end and step values, and the
step can be negative. We might also like to handle alternative types, such as
unsigned or double, and we need to ensure we handle things like empty
ranges.
Alternative types is mostly easy: just make numeric_range a class template,
and replace int with our new template parameter T everywhere.
Setting the initial and final values is also easy: just provide a new constructor that takes both the current and final values, rather than initializing the current value to 0.
Steps are a bit more tricky: if the final value is not initial+n*step for an
integer n, then the direct comparison of current==final to check for the end
of the sequence won't work, as it will always be false. We therefore need to
check for current>=final, to account for overshoot. This then doesn't work for
negative steps, so we need to allow for that too: if the step is negative, we
check for current<=final instead.
Final code
The final code is available for download with simple examples, under the BSD license.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, ranges, iteration
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Reclaiming Data Structures with Cycles
Friday, 14 October 2016
In my CppCon 2016 Trip Report I mentioned Herb Sutter's Plenary, and his deferred reclamation library. The problem to be solved is that some data structures cannot be represented as a DAG, where each node in the structure has a clear owner; these data structures are general graphs, where any node may hold a pointer to any other node, and thus you cannot say that a node is no longer needed just because one of the pointers to it has been removed. Likewise, it is possible that there may be a whole segment of the data structure which is no longer accessible from outside, and the only remaining pointers are those internal to the data structure. This whole section should therefore be destroyed, otherwise we have a leak.
In the data structure shown below, the left-hand set of nodes have 3 external pointers keeping them alive, but the right-hand set are not accessible from outside, and so should be destroyed.
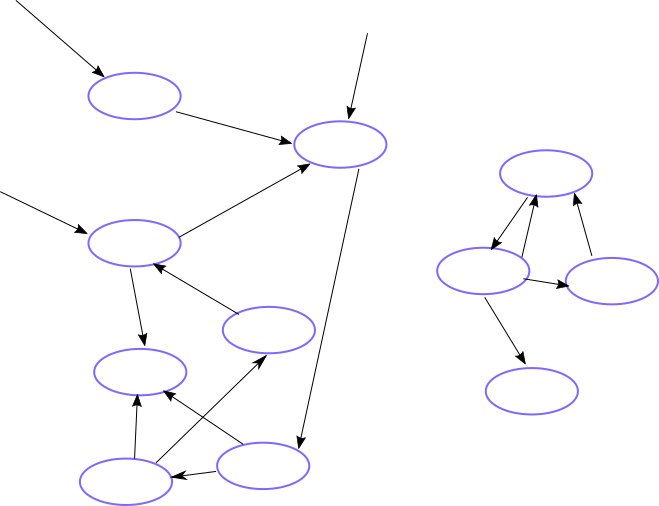
Deferred Reclamation
Herb's solution is to use a special pointer type deferred_ptr<T>, and a
special heap and allocator to create the nodes. You can then explicitly check
for inaccessible nodes by calling collect() on the heap object, or rely on all
the nodes being destroyed when the heap itself is destroyed. For the details,
see Herb's description.
One thing that stood out for me was the idea that destruction was deferred — nodes are not reclaimed immediately, but at some later time. Also, the use of a custom allocator seemed unusual. I wondered if there was an alternative way of handling things.
Internal pointers vs Root pointers
I've been contemplating the issue for the last couple of weeks, and come up with an alternative scheme that destroys unreachable objects as soon as they become unreachable, even if those unreachable objects hold pointers to each other. Rather than using a custom heap and allocator, it uses a custom base class, and distinct pointer types for internal pointers and root pointers.
My library is also still experimental, but the source code is freely available under the BSD license.
The library provides two smart pointer class templates: root_ptr<T> and
internal_ptr<T>. root_ptr<T> is directly equivalent to
std::shared_ptr<T>: it is a reference-counted smart pointer. For many uses,
you could use root_ptr<T> as a direct replacement for std::shared_ptr<T>
and your code will have identical behaviour. root_ptr<T> is intended to
represent an external owner for your data structure. For a tree it could
hold the pointer to the root node. For a general graph it could be used to hold
each of the external nodes of the graph.
The difference comes with internal_ptr<T>. This holds a pointer to another
object within the data structure. It is an internal pointer to another
part of the same larger data structure. It is also reference counted, so if
there are no root_ptr<T> or internal_ptr<T> objects pointing to a given
object then it is immediately destroyed, but even one internal_ptr<T> can be
enough to keep an object alive as part of a larger data structure.
The "magic" is that if an object is only pointed to by internal_ptr<T>
pointers, then it is only kept alive as long as the whole data structure has an
accessible root in the form of an root_ptr<T> or an object with an
internal_ptr<T> that is not pointed to by either an root_ptr<T> or an
internal_ptr<T>.
This is made possible by the internal nodes deriving from internal_base, much
like std::enable_shared_from_this<T> enables additional functionality when
using std::shared_ptr<T>. This base class is then passed to the
internal_ptr<T> constructor, to identify which object the internal_ptr<T>
belongs to.
For example, a singly-linked list could be implemented like so:
class List{
struct Node: jss::internal_base{
jss::internal_ptr<Node> next;
data_type data;
Node(data_type data_):next(this),data(data_){}
};
jss::root_ptr<Node> head;
public:
void push_front(data_type new_data){
auto new_node=jss::make_owner<Node>(new_data);
new_node->next=head;
head=new_node;
}
data_type pop_front(){
auto old_head=head;
if(!old_head)
throw std::runtime_error("Empty list");
head=old_head->next;
return old_head->data;
}
void clear(){
head.reset();
}
};This actually has an advantage over using std::shared_ptr<Node> for the links
in the list, due to another feature of the library. When a group of interlinked
nodes becomes unreachable, then firstly each node is marked as unreachable, thus
making any internal_ptr<T>s that point to them become equal to nullptr. Then
all the unreachable nodes are destroyed in turn. All this is done with iteration
rather than recursion, and thus avoids the deep recursive destructor chaining
that can occur when using std::shared_ptr<T>. This is similar to the behaviour
of Herb's deferred_ptr<T> during a collect() call on the deferred_heap.
local_ptr<T> completes the set: you can use a local_ptr<T> when traversing a
data structure that uses internal_ptr<T>. local_ptr<T> does not hold a
reference, and is not in any way involved in the lifetime tracking of the
nodes. It is intended to be used when you need to keep a local pointer to a
node, but you're not updating the data structure, and don't need that pointer to
keep the node alive. e.g.
class List{
// as above
public:
void for_each(std::function<void(data_type&)> f){
jss::local_ptr<Node> node=head;
while(node){
f(node->data);
node=node->next;
}
}
}Warning: root_ptr<T> and internal_ptr<T> are not safe for use if
multiple threads may be accessing any of the nodes in the data structure while
any thread is modifying any part of it. The data structure as a whole
must be protected with external synchronization in a multi-threaded context.
How it works
The key to this system is twofold. Firstly the nodes in the data structure
derive from internal_base, which allows the library to store a back-pointer to
the smart pointer control block in the node itself, as long as the head of the
list of internal_ptr<T>s that belong to that node. Secondly, the control
blocks each hold a list of back-pointers to the control blocks of the objects
that point to them via internal_ptr<T>. When a reference to a node is dropped
(either from an root_ptr<T> or an internal_ptr<T>), if that node has no
remaining root_ptr<T>s that point to it, the back-pointers are checked. The
chain of back-pointers is followed until either a node is found that has an
root_ptr<T> that points to it, or a node is found that does not have a
control block (e.g. because it is allocated on the stack, or owned by
std::shared_ptr<T>). If either is found, then the data structure is
reachable, and thus kept alive. If neither is found once all the
back-pointers have been followed, then the set of nodes that were checked is
unreachable, and thus can be destroyed. Each of the unreachable nodes is then
marked as such, which causes internal_ptr<T>s that refer to them to become
nullptr, and thus prevents resurrection of the nodes. Finally, the unreachable
nodes are all destroyed in an unspecified order. The scan and destroy is done
with iteration rather than recursion to avoid the potential for deep recursive
nesting on large interconnected graphs of nodes.
The downside is that the time taken to drop a reference to a node is dependent on the number of nodes in the data structure, in particular the number of nodes that have to be examined in order to find an owned node.
Note: only dropping a reference to a node (destroying a pointer, or reassigning a pointer) incurs this cost. Constructing the data structure is still relatively low overhead.
Feedback
Please let me know if you have any comments on my internal pointer library, especially if you have either used it successfully, or have tried to use it and found it doesn't work for you.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, reference counting, garbage collection
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Core C++ - lvalues and rvalues
Saturday, 27 February 2016
One of the most misunderstood aspect of C++ is the use of the terms lvalue and rvalue, and what they mean for how code is interpreted. Though lvalue and rvalue are inherited from C, with C++11, this taxonomy was extended and clarified, and 3 more terms were added: glvalue, xvalue and prvalue. In this article I'm going to examine these terms, and explain what they mean in practice.
Before we discuss the importance of whether something is an lvalue or rvalue, let's take a look at what makes an expression have each characteristic.
The Taxonomy
The result of every C++ expression is either an lvalue, or an rvalue. These terms come from C, but the C++ definitions have evolved quite a lot since then, due to the greater expressiveness of the C++ language.
rvalues can be split into two subcategories: xvalues, and prvalues, depending on the details of the expression. These subcategories have slightly different properties, described below.
One of the differences is that xvalues can sometimes be treated the same as lvalues. To cover those cases we have the term glvalue — if something applies to both lvalues and xvalues then it is described as applying to glvalues.
Now for the definitions.
glvalues
A glvalue is a Generalized lvalue. It is used to refer to something that could be either an lvalue or an xvalue.
rvalues
The term rvalue is inherited from C, where rvalues are things that can be on the Right side of an assignment. The term rvalue can refer to things that are either xvalues or prvalues.
lvalues
The term lvalue is inherited from C, where lvalues are things that can be on the Left side of an assignment.
The simplest form of lvalue expression is the name of a variable. Given a variable declaration:
A v1;
The expression v1 is an lvalue of type A.
Any expression that results in an lvalue reference (declared with &) is also
an lvalue, so the result of dereferencing a pointer, or calling a function
that returns an lvalue reference is also an lvalue. Given the following
declarations:
A* p1;
A& r1=v1;
A& f1();
The expression *p1 is an lvalue of type A, as is the expression f1() and
the expression r1.
Accessing a member of an object where the object expression is an lvalue is also an lvalue. Thus, accessing members of variables and members of objects accessed through pointers or references yields lvalues. Given
struct B{
A a;
A b;
};
B& f2();
B* p2;
B v2;then f2().a, p2->b and v2.a are all lvalues of type A.
String literals are lvalues, so "hello" is an lvalue of type array of 6
const chars (including the null terminator). This is distinct from other
literals, which are prvalues.
Finally, a named object declared with an rvalue reference (declared with &&)
is also an lvalue. This is probably the most confusing of the rules, if for no
other reason than that it is called an rvalue reference. The name is just
there to indicate that it can bind to an rvalue (see later); once you've
declared a variable and given it a name it's an lvalue. This is most commonly
encountered in function parameters. For example:
void foo(A&& a){
}Within foo, a is an lvalue (of type A), but it will only bind to rvalues.
xvalues
An xvalue is an eXpiring value: an unnamed objects that is soon to be destroyed. xvalues may be either treated as glvalues or as rvalues depending on context.
xvalues are slightly unusual in that they usually only arise through explicit
casts and function calls. If an expression is cast to an rvalue reference to
some type T then the result is an xvalue of type
T. e.g. static_cast<A&&>(v1) yields an xvalue of type A.
Similarly, if the return type of a function is an rvalue reference to some
type T then the result is an xvalue of type T. This is the case with
std::move(), which is declared as:
template <typename T>
constexpr remove_reference_t<T>&&
move(T&& t) noexcept;Thus std::move(v1) is an xvalue of type A — in this case, the type
deduction rules deduce T to be A& since v1 is an lvalue, so
the return type is declared to be A&& as remove_reference_t<A&> is just A.
The only other way to get an xvalue is by accessing a member of an
rvalue. Thus expressions that access members of temporary objects
yield xvalues, and the expression B().a is an xvalue of type A, since
the temporary object B() is a prvalue. Similarly,
std::move(v2).a is an xvalue, because std::move(v2) is an xvalue, and
thus an rvalue.
prvalues
A prvalue is a Pure rvalue; an rvalue that is not an xvalue.
Literals other than string literals (which are lvalues) are
prvalues. So 42 is a prvalue of type int, and 3.141f is a prvalue
of type float.
Temporaries are also prvalues. Thus given the definition of A above, the
expression A() is a prvalue of type A. This applies to all temporaries:
any temporaries created as a result of implicit conversions are thus also
prvalues. You can therefore write the following:
int consume_string(std::string&& s);
int i=consume_string("hello");as the string literal "hello" will implicitly convert to a temporary of type
std:string, which can then bind to the rvalue reference used for the
function parameter, because the temporary is a prvalue.
Reference binding
Probably the biggest difference between lvalues and rvalues is in how they bind to references, though the differences in the type deduction rules can have a big impact too.
There are two types of references in C++: lvalue references, which are
declared with a single ampersand, e.g. T&, and rvalue references which are
declared with a double ampersand, e.g. T&&.
lvalue references
A non-const lvalue reference will only bind to non-const
lvalues of the same type, or a class derived from the referenced
type.
struct C:A{};
int i=42;
A a;
B b;
C c;
const A ca{};
A& r1=a;
A& r2=c;
//A& r3=b; // error, wrong type
int& r4=i;
// int& r5=42; // error, cannot bind rvalue
//A& r6=ca; // error, cannot bind const object to non const ref
A& r7=r1;
// A& r8=A(); // error, cannot bind rvalue
// A& r9=B().a; // error, cannot bind rvalue
// A& r10=C(); // error, cannot bind rvalueA const lvalue reference on the other hand will also bind to
rvalues, though again the object bound to the reference must have
the same type as the referenced type, or a class derived from the referenced
type. You can bind both const and non-const values to a const lvalue
reference.
const A& cr1=a;
const A& cr2=c;
//const A& cr3=b; // error, wrong type
const int& cr4=i;
const int& cr5=42; // rvalue can bind OK
const A& cr6=ca; // OK, can bind const object to const ref
const A& cr7=cr1;
const A& cr8=A(); // OK, can bind rvalue
const A& cr9=B().a; // OK, can bind rvalue
const A& cr10=C(); // OK, can bind rvalue
const A& cr11=r1;If you bind a temporary object (which is a prvalue) to a const
lvalue reference, then the lifetime of that temporary is extended to the
lifetime of the reference. This means that it is OK to use r8, r9 and r10
later in the code, without running the undefined behaviour that would otherwise
accompany an access to a destroyed object.
This lifetime extension does not extend to references initialized from the first
reference, so if a function parameter is a const lvalue reference, and gets bound
to a temporary passed to the function call, then the temporary is destroyed when
the function returns, even if the reference was stored in a longer-lived
variable, such as a member of a newly constructed object. You therefore need to
take care when dealing with const lvalue references to ensure that you
cannot end up with a dangling reference to a destroyed temporary.
volatile and const volatile lvalue references are much less interesting,
as volatile is a rarely-used qualifier. However, they essentially behave as
expected: volatile T& will bind to a volatile or non-volatile, non-const
lvalue of type T or a class derived from T, and volatile const T& will bind to any lvalue of type T or a class derived from
T. Note that volatile const lvalue references do not bind to rvalues.
rvalue references
An rvalue reference will only bind to rvalues of the same
type, or a class derived from the referenced type. As for lvalue references,
the reference must be const in order to bind to a const object, though
const rvalue references are much rarer than const lvalue references.
const A make_const_A();
// A&& rr1=a; // error, cannot bind lvalue to rvalue reference
A&& rr2=A();
//A&& rr3=B(); // error, wrong type
//int&& rr4=i; // error, cannot bind lvalue
int&& rr5=42;
//A&& rr6=make_const_A(); // error, cannot bind const object to non const ref
const A&& rr7=A();
const A&& rr8=make_const_A();
A&& rr9=B().a;
A&& rr10=C();
A&& rr11=std::move(a); // std::move returns an rvalue
// A&& rr12=rr11; // error rvalue references are lvaluesrvalue references extend the lifetime of temporary objects in the same way
that const lvalue references do, so the temporaries associated with rr2,
rr5, rr7, rr8, rr9, and rr10 will remain alive until the
corresponding references are destroyed.
Implicit conversions
Just because a reference won't bind directly to the value of an expression, doesn't mean you can't initialize it with that expression, if there is an implicit conversion between the types involved.
For example, if you try and initialize a reference-to-A with a D object, and
D has an implicit conversion operator that returns an A& then all is well,
even though the D object itself cannot bind to the reference: the reference is
bound to the result of the conversion operator.
struct D{
A a;
operator A&() {
return a;
}
};
D d;
A& r=d; // reference bound to result of d.operator A&()Similarly, a const lvalue-reference-to-E will bind to an A object if A
is implicitly convertible to E, such as with a conversion constructor. In this
case, the reference is bound to the temporary E object that results from the
conversion (which therefore has its lifetime extended to match that of the
reference).
struct E{
E(A){}
};
const E& r=A(); // reference bound to temporary constructed with E(A())This allows you to pass string literals to functions taking std::string by
const reference:
void foo(std::string const&);
foo("hello"); // ok, reference is bound to temporary std::string objectOther Properties
Whether or not an expression is an lvalue or rvalue can affect a few other aspects of your program. These are briefly summarised here, but the details are out of scope of this article.
In general, rvalues cannot be modified, nor can they have their
address taken. This means that simple expressions like A()=something or &A()
or &42 are ill-formed. However, you can call member functions on
rvalues of class type, so X().do_something() is valid (assuming
class X has a member function do_something).
Class member functions can be tagged with ref qualifiers to indicate that they
can be applied to only rvalues or only lvalues. ref
qualifiers can be combined with const, and can be used to distinguish
overloads, so you can define different implementations of a function depending
whether the object is an lvalue or rvalue.
When the type of a variable or function template parameter is deduce from its initializer, whether the initializer is an lvalue or rvalue can affect the deduced type.
End Note
rvalues and lvalues are a core part of C++, so understanding them is essential. Hopefully, this article has given you a greater understanding of their properties, and how they relate to the rest of C++.
If you liked this article, please share with the buttons below. If you have any questions or comments, please submit them using the comment form.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, lvalues, rvalues
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Core C++ - Destructors and RAII
Thursday, 24 September 2015
Though I love many features of C++, the feature that I think is probably the most important for writing robust code is deterministic destruction and destructors.
The destructor for an object is called when that object is destroyed, whether explicitly with the delete operator, or implicitly when it goes out of scope. This provides an opportunity to clean up any resources held by that object, thus making it easy to avoid leaking memory, or indeed any kind of resource.
This has led to the idiom commonly known as Resource Acquisition Is Initialization (RAII) — a class acquires some resource when it is initialised (in its constructor), and then releases it in its destructor. A better acronym would be DIRR — Destruction Is Resource Release — as the release in the destructor is the important part, but RAII is what has stuck.
The power of RAII
This is incredibly powerful, and makes it so much easier to write robust
code. It doesn't matter how the object goes out of scope, whether it is due to
just reaching the end of the block, or due to a control transfer statement such
as goto, break or continue, or because the function has returned, or
because an exception is thrown. However the object is destroyed, the destructor
is run.
This means you don't have to litter your code with calls to cleanup functions. You just write a class to manage a resource and have the destructor call the cleanup function. Then you can just create objects of that type and know that the resource will be correctly cleaned up when the object is destroyed.
No more leaks
If you don't use resource management classes, it can be hard to ensure that your resources are correctly released on all code paths, especially in the presence of exceptions. Even without exceptions, it's easy to fail to release a resource on a rarely-executed code path. How many programs have you seen with memory leaks?
Writing a resource management class for a particular resource is really easy,
and there are many already written for you. The C++ standard is full of
them. There are the obvious ones like std::unique_ptr and std::shared_ptr
for managing heap-allocated objects, and std::lock_guard for managing lock
ownership, but also std::fstream and std::file_buf for managing file
handles, and of course all the container types.
I like to use std::vector<char> as a generic buffer-management class for
handling buffers for legacy C-style APIs. The always-contiguous guarantee means
that it's great for anything that needs a char buffer, and there is no messing
around with reallocor the potential for buffer overrun you get with fixed-size
buffers.
For example, many Windows API calls take a buffer in which they return the
result, as well as a length parameter to specify how big the buffer is. If the
buffer isn't big enough, they return the required buffer size. We can use this
with std::vector<char> to ensure that our buffer is big enough. For example,
the following code retrieves the full path name for a given relative path,
without requiring any knowledge about how much space is required beforehand:
std::string get_full_path_name(std::string const& relative_path){
DWORD const required_size=GetFullPathName(relative_path.c_str(),0,NULL,&filePart);
std::vector<char> buffer(required_size);
if(!GetFullPathName(relative_path.c_str(),buffer.size(),buffer.data(),&filePart))
throw std::runtime_error("Unable to retrieve full path name");
return std::string(buffer.data());
}Nowhere do we need to explicitly free the buffer: the destructor takes care of that for us, whether we return successfully or throw. Writing resource management classes enables us to extend this to every type of resource: no more leaks!
Writing resource management classes
A basic resource management class needs just two things: a constructor that takes ownership of the resource, and a destructor that releases ownership. Unless you need to transfer ownership of your resource between scopes you will also want to prevent copying or moving of your class.
class my_resource_handle{
public:
my_resource_handle(...){
// acquire resource
}
~my_resource_handle(){
// release resource
}
my_resource_handle(my_resource_handle const&)=delete;
my_resource_handle& operator=(my_resource_handle const&)=delete;
};Sometimes the resource ownership might be represented by some kind of token,
such as a file handle, whereas in other cases it might be more conceptual, like
a mutex lock. Whatever the case, you need to store enough data in your class to
ensure that you can release the resource in the destructor. Sometimes you might
want your class to take ownership of a resource acquired elsewhere. In this
case, you can provide a constructor to do that. std::lock_guard is a nice
example of a resource-ownership class that manages an ephemeral resource, and
can optionally take ownership of a resource acquired elsewhere. It just holds a
reference to the lockable object being locked and unlocked; the ownership of the
lock is implicit. The first constructor always acquires the lock itself, whereas
the second constructor taking an adopt_lock_t parameter allows it to take
ownership of a lock acquired elsewhere.
template<typename Lockable>
class lock_guard{
Lockable& lockable;
public:
explicit lock_guard(Lockable& lockable_):
lockable(lockable_){
lockable.lock();
}
explicit lock_guard(Lockable& lockable_,adopt_lock_t):
lockable(lockable_){}
~lock_guard(){
lockable.unlock();
}
lock_guard(lock_guard const&)=delete;
lock_guard& operator=(lock_guard const&)=delete;
};Using std::lock_guard to manage your mutex locks means you no longer have to
worry about ensuring that your mutexes are unlocked when you exit a function:
this just happens automatically, which is not only easy to manage conceptually,
but less typing too.
Here is another simple example: a class that saves the state of a Windows GDI DC, such as the current pen, font and colours.
class dc_saver{
HDC dc;
int state;
public:
dc_saver(HDC dc_):
dc(dc_),state(SaveDC(dc)){
if(!state)
throw std::runtime_error("Unable to save DC state");
}
~dc_saver(){
RestoreDC(dc,state);
}
dc_saver(dc_saver const&)=delete;
dc_saver& operator=(dc_saver const&)=delete;
};You could use this as part of some drawing to save the state of the DC before changing it for local use, such as setting a new font or new pen colour. This way, you know that whatever the state of the DC was when you started your function, it will be safely restored when you exit, even if you exit via an exception, or you have multiple return points in your code.
void draw_something(HDC dc){
dc_saver guard(dc);
// set pen, font etc.
// do drawing
} // DC properties are always restored hereAs you can see from these examples, the resource being managed could be anything: a file handle, a database connection handle, a lock, a saved graphics state, anything.
Transfer season
Sometimes you want to transfer ownership of the resource between scopes. The classical use case for this is you have some kind of factory function that acquires the resource and then returns a handle to the caller. If you make your resource management class movable then you can still benefit from the guaranteed leak protection. Indeed, you can build it in at the source: if your factory returns an instance of your resource management rather than a raw handle then you are protected from the start. If you never expose the raw handle, but instead provide additional functions in the resource management class to interact with it, then you are guaranteed that your resource will not leak.
std::async provides us with a nice example of this in action. When you start a
task with std::async, then you get back a std::future object that references
the shared state. If your task is running asynchronously, then the destructor
for the future object will wait for the task to complete. You can, however, wait
explicitly beforehand, or return the std::future to the caller of your
function in order to transfer ownership of the "resource": the running
asynchronous task.
You can add such ownership-transfer facilities to your own resource management classes without much hassle, but you need to ensure that you don't end up with multiple objects thinking they own the same resource, or resources not being released due to mistakes in the transfer code. This is why we start with non-copyable and non-movable classes by deleting the copy operations: then you can't accidentally end up with botched ownership transfer, you have to write it explicitly, so you can ensure you get it right.
The key part is to ensure that not only does the new instance that is taking ownership of the resource hold the proper details to release it, but the old instance will no longer try and release the resource: double-frees can be just as bad as leaks.
std::unique_lock is the big brother of std::lock_guard that allows transfer
of ownership. It also has a bunch of additional member functions for acquiring
and releasing locks, but we're going to focus on just the move semantics. Note:
it is still not copyable: only one object can own a given lock, but we can
change which object that is.
template<typename Lockable>
class unique_lock{
Lockable* lockable;
public:
explicit unique_lock(Lockable& lockable_):
lockable(&lockable_){
lockable->lock();
}
explicit unique_lock(Lockable& lockable_,adopt_lock_t):
lockable(&lockable_){}
~unique_lock(){
if(lockable)
lockable->unlock();
}
unique_lock(unique_lock && other):
lockable(other.lockable){
other.lockable=nullptr;
}
unique_lock& operator=(unique_lock && other){
unique_lock temp(std::move(other));
std::swap(lockable,temp.lockable);
return *this;
}
unique_lock(unique_lock const&)=delete;
unique_lock& operator=(unique_lock const&)=delete;
};Firstly, see how in order to allow the assignment, we have to hold a pointer to
the Lockable object rather than a reference, and in the destructor we have to
check whether or not the pointer is nullptr. Secondly, see that in the move
constructor we explicitly set the pointer to nullptrfor the source of our
move, so that the source will no longer try and release the lock in its
destructor.
Finally, look at the move-assignment operator. We have explicitly transferred
ownership from the source object into a new temporary object, and then swapped
the resources owned by the target object and our temporary. This ensures that
when the temporary goes out of scope, its destructor will release the lock
owned by our target beforehand, if there was one. This is a common pattern among
resource management classes that allow ownership transfer, as it keeps
everything tidy without having to explicitly write the resource cleanup code in
more than one place. If you've written a swap function for your class then you
might well use that here rather than directly exchanging the members, to avoid
duplication.
Wrapping up
Using resource management classes can simplify your code, and reduce the need for debugging, so use RAII for all your resources to avoid leaks and other resource management issues. There are many classes already provided in the C++ Standard Library or third-party libraries, but it is trivial to write your own resource management wrapper for any resource if there is a well-defined API for acquiring and releasing the resource.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, destructors, RAII
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
std::shared_ptr's secret constructor
Friday, 24 July 2015
std::shared_ptr has a secret: a constructor that most users don't even know
exists, but which is surprisingly useful. It was added during the lead-up to the
C++11 standard, so wasn't in the TR1 version of shared_ptr, but it's been
shipped with gcc since at least gcc 4.3, and with Visual Studio since Visual
Studio 2010, and it's been in Boost since at least v1.35.0.
This constructor doesn't appear in most tutorials on std::shared_ptr. Nicolai
Josuttis devotes half a page to this constructor in the second edition of The
C++ Standard Library, but Scott Meyers doesn't even mention it in his item on
std::shared_ptr in Effective Modern C++.
So: what is this constructor? It's the aliasing constructor.
Aliasing shared_ptrs
What does this secret constructor do for us? It allows us to construct a new
shared_ptr instance that shares ownership with another shared_ptr, but which
has a different pointer value. I'm not talking about a pointer value that's just
been cast from one type to another, I'm talking about a completely different
value. You can have a shared_ptr<std::string> and a shared_ptr<double> share
ownership, for example.
Of course, only one pointer is ever owned by a given set of shared_ptr
objects, and only that pointer will be deleted when the objects are
destroyed. Just because you can create a new shared_ptr that holds a different
value, you don't suddenly get the second pointer magically freed as well. Only
the original pointer value used to create the first shared_ptr will be
deleted.
If your new pointer values don't get freed, what use is this constructor? It
allows you to pass out shared_ptr objects that refer to subobjects and keep
the parent alive.
Sharing subobjects
Suppose you have a class X with a member that is an instance of some class Y:
struct X{
Y y;
};Now, suppose you have a dynamically allocated instance of X that you're
managing with a shared_ptr<X>, and you want to pass the Y member to a
library that takes a shared_ptr<Y>. You could construct a shared_ptr<Y> that
refers to the member, with a do-nothing deleter, so the library doesn't actually
try and delete the Y object, but what if the library keeps hold of the
shared_ptr<Y> and our original shared_ptr<X> goes out of scope?
struct do_nothing_deleter{
template<typename> void operator()(T*){}
};
void store_for_later(std::shared_ptr<Y>);
void foo(){
std::shared_ptr<X> px(std::make_shared<X>());
std::shared_ptr<Y> py(&px->y,do_nothing_deleter());
store_for_later(py);
} // our X object is destroyedOur stored shared_ptr<Y> now points midway through a destroyed object, which
is rather undesirable. This is where the aliasing constructor comes in: rather
than fiddling with deleters, we just say that our shared_ptr<Y> shares
ownership with our shared_ptr<X>. Now our shared_ptr<Y> keeps our X object
alive, so the pointer it holds is still valid.
void bar(){
std::shared_ptr<X> px(std::make_shared<X>());
std::shared_ptr<Y> py(px,&px->y);
store_for_later(py);
} // our X object is kept aliveThe pointer doesn't have to be directly related at all: the only requirement is
that the lifetime of the new pointer is at least as long as the lifetime of the
shared_ptr objects that reference it. If we had a new class X2 that held a
dynamically allocated Y object we could still use the aliasing constructor to
get a shared_ptr<Y> that referred to our dynamically-allocated Y object.
struct X2{
std::unique_ptr<Y> y;
X2():y(new Y){}
};
void baz(){
std::shared_ptr<X2> px(std::make_shared<X2>());
std::shared_ptr<Y> py(px,px->y.get());
store_for_later(py);
} // our X2 object is kept aliveThis could be used for classes that use the pimpl idiom, or trees where you
want to be able to pass round pointers to the child nodes, but keep the whole
tree alive. Or, you could use it to keep a shared library alive as long as a
pointer to a variable stored in that library was being used. If our class X
loads the shared library in its constructor and unloads it in the destructor,
then we can pass round shared_ptr<Y> objects that share ownership with our
shared_ptr<X> object to keep the shared library from being unloaded until all
the shared_ptr<Y> objects have been destroyed or reset.
The details
The constructor signature looks like this:
template<typename Other,typename Target>
shared_ptr(shared_ptr<Other> const& other,Target* p);As ever, if you're constructing a shared_ptr<T> then the pointer p must be
convertible to a T*, but there's no restriction on the type of Other at
all. The newly constructed object shares ownership with other, so
other.use_count() is increased by 1, and the value returned by get() on the
new object is static_cast<T*>(p).
There's a slight nuance here: if other is an empty shared_ptr, such as a
default-constructed shared_ptr, then the new shared_ptr is also empty, and
has a use_count() of 0, but it has a non-NULL value if p was not
NULL.
int i;
shared_ptr<int> sp(shared_ptr<X>(),&i);
assert(sp.use_count()==0);
assert(sp.get()==&i);Whether this odd effect has any use is open to debate.
Final Thoughts
This little-known constructor is potentially very useful for passing around
shared_ptr objects that reference parts of a non-trivial data structure and
keep the whole data structure alive. Not everyone will need it, but for those
that do it will avoid a lot of headaches.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: shared_ptr, cplusplus
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Standardizing Variant: Difficult Decisions
Wednesday, 17 June 2015
One of the papers proposed for the next version of the C++ Standard is N4542: Variant: a type safe union (v4). As you might guess from the (v4) in the title, this paper has been discussed several times by the committee, and revised in the light of discussions.
Boost has had a variant type for a long time, so it only
seems natural to standardize it. However, there are a couple of design decisions
made for boost::variant which members of the committee were uncomfortable
with, so the current paper has a couple of differences from
boost::variant. The most notable of these is that boost::variant has a
"never empty" guarantee, whereas N4542 proposes a variant that can be empty.
Why do we need empty variants?
Let's assume for a second that our variant is never empty, as per
boost::variant, and consider the following code with two classes A and B:
variant<A,B> v1{A()};
variant<A,B> v2{B()};
v1=v2;Before the assignment, v1 holds a value of type A. After the assignment
v1=v2, v1 has to hold a value of type B, which is a copy of the value held
in v2. The assignment therefore has to destroy the old value of type A and
copy-construct a new value of type B into the internal storage of v1.
If the copy-construction of B does not throw, then all is well. However, if
the copy construction of B does throw then we have a problem: we just
destroyed our old value (of type A), so we're in a bit of a predicament
— the variant isn't allowed to be empty, but we don't have a value!
Can we fix it? Double buffering
In 2003 I wrote
an article about this,
proposing a solution involving double-buffering: the variant type could contain
a buffer big enough to hold both A and B. Then, the assignment operator
could copy-construct the new value into the empty space, and only destroy the
old value if this succeeded. If an exception was thrown then the old value is
still there, so we avoid the previous predicament.
This technique isn't without downsides though. Firstly, this can double the size of the variant, as we need enough storage for the two largest types in the variant. Secondly, it changes the order of operations: the old value is not destroyed until after the new one has been constructed, which can have surprising consequences if you are not expecting it.
The current implementation of boost::variant avoids the first problem by
constructing the secondary buffer on the fly. This means that assignment of
variants now involves dynamic memory allocation, but does avoid the double-space
requirement. However, there is no solution for the second problem: avoiding
destroying the old value until after the new one has been constructed cannot be
avoided while maintaining the never-empty guarantee in the face of throwing copy
constructors.
Can we fix it? Require no-throw copy construction
Given that the problem only arises due to throwing copy constructors, we could easily avoid the problem by requiring that all types in the variant have a no-throw copy constructor. The assignment is then perfectly safe, as we can destroy the old value, and copy-construct the new one, without fear of an exception throwing a spanner in the works.
Unfortunately, this has a big downside: lots of useful types that people want to
put in variants like std::string, or std::vector, have throwing copy
constructors, since they must allocate memory, and people would now be unable to
store them directly. Instead, people would have to use
std::shared_ptr<std::string> or create a wrapper that stored the exception in
the case that the copy constructor threw an exception.
template<typename T>
class value_or_exception{
private:
std::optional<T> value;
std::exception_ptr exception;
public:
value_or_exception(T const& v){
try{
value=v;
} catch(...) {
exception=std::current_exception();
}
}
value_or_exception(value_or_exception const& v){
try{
value=v.value;
exception=v.exception;
} catch(...) {
exception=std::current_exception();
}
return *this;
}
value_or_exception& operator=(T const& v){
try{
value=v;
exception=std::exception_ptr();
} catch(...) {
exception=std::current_exception();
}
return *this;
}
// more constructors and assignment operators
T& get(){
if(exception){
std::rethrow_exception(exception);
}
return *value;
}
};Given such a template you could have
variant<int,value_or_exception<std::string>>, since the copy constructor would
not throw. However, this would make using the std::string value that little
bit harder due to the wrapper — access to it would require calling get()
on the value, in addition to the code required to retrieve it from the variant.
variant<int,value_or_exception<std::string>> v=get_variant_from_somewhere();
std::string& s=std::get<value_or_exception<std::string>>(v).get();The code that retrieves the value then also needs to handle the case that the
variant might be holding an exception, so get() might throw.
Can we fix it? Tag types
One proposed solution is to add a special case if one of the variant types is a
special tag type like
empty_variant_t. e.g. variant<int,std::string,empty_variant_t. In this case,
if the copy constructor throws then the special empty_variant_t type is stored
in the variant instead of what used to be there, or what we tried to
assign. This allows people who are OK with the variant being empty to use this
special tag type as a marker — the variant is never strictly "empty", it
just holds an instance of the special type in the case of an exception, which
avoids the problems with out-of-order construction and additional
storage. However, it leaves the problems for those that don't want to use the
special tag type, and feels like a bit of a kludge.
Do we need to fix it?
Given the downsides, we have to ask: is any of this really any better than allowing an empty state?
If we allow our variant to be empty then the code is simpler: we just write
for the happy path in the main code. If the assignment throws then we will get
an exception at that point, which we can handle, and potentially store a new
value in the variant there. Also, when we try and retrieve the value then we
might get an exception there if the variant is empty. However, if the expected
scenario is that the exception will never actually get thrown, and if it does
then we have a catastrophic failure anyway, then this can greatly simplify the
code.
For example, in the case of variant<int,std::string>, the only reason
you'd get an exception from the std::string copy constructor was due to
insufficient memory. In many applications, running out of dynamic memory is
exceedingly unlikely (the OS will just allocate swap space), and indicates an
unrecoverable scenario, so we can get away with assuming it won't happen. If our
application isn't one of these, we probably know it, and will already be writing
code to carefully handle out-of-memory conditions.
Other exceptions might not be so easily ignorable, but in those cases you probably also have code designed to handle the scenario gracefully.
A variant with an "empty" state is a bit like a pointer in the sense that you
have to check for NULL before you use it, whereas a variant without an empty
state is more like a reference in that you can rely on it having a value. I can
see that any code that handles variants will therefore get filled with asserts
and preconditions to check the non-emptiness of the variant.
Given the existence of an empty variant, I would rather that the various
accessors such as get<T>() and get<Index>() threw an exception on the empty
state, rather than just being ill-formed.
Default Construction
Another potentially contentious area is that of default construction: should a
variant type be default constructible? The current proposal has variant<A,B>
being default-constructible if and only if A (the first listed type) is
default-constructible, in which case the default constructor default-constructs an
instance of A in the variant. This mimics the behaviour of the core language
facility union.
This means that variant<A,B> and variant<B,A> behave differently with
respect to default construction. For starters, the default-constructed type is
different, but also one may be default-constructible while the other is not. For
some people this is a surprising result, and undesirable.
One alternative options is that default construction picks the first default-constructible type from the list, if there are any, but this still has the problem of different orderings behaving differently.
Given that variants can be empty, another alternative is to have the default constructed variant be empty. This avoids the problem of different orderings behaving differently, and will pick up many instances of people forgetting to initialize their variants, since they will now be empty rather than holding a default-constructed value.
My preference is for the third option: default constructed variants are empty.
Duplicate types
Should we allow variant<T,T>? The current proposal allows it, and makes the
values distinct. However, it comes with a price: you cannot simply construct a
variant<T,T> from a T: instead you must use the special constructors that
take an emplaced_index_t<I> as the first parameter, to indicate which entry
you wish to construct. Similarly, you can now no longer retrieve the value
merely by specifying the type to retrieve: you must specify the index, as this
is now significant.
I think this is unnecessary overhead for a seriously niche feature. If people
want to have two entries of the same type, but with different meanings, in their
variant then they should use the type system to make them different. It's
trivial to write a tagged_type template, so you can have tagged_type<T,struct SomeTag>and tagged_type<T,struct OtherTag> which are distinct types, and thus
easily discriminated in the variant. Many people would argue that even this is
not going far enough: you should embrace the Whole Value Idiom, and write a
proper class for each distinct meaning.
Given that, I think it thus makes sense for variant<T,T> to be ill-formed. I'm
tempted to make it valid, and the same as variant<T>, but too much of the
interface depends on the index of the type in the type list. If I have
variant<T,U,T,T,U,int>, what is the type index of the int, or the T for
that matter? I'd rather not have to answer such questions, so it seems better to
make it ill-formed.
What do you think?
What do you think about the proposed variant template? Do you agree with the design decisions? Do you have a strong opinion on the issues above, or some other aspect of the design?
Have your say in the comments below.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, standards, variant
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Using Enum Classes as Bitfields
Thursday, 29 January 2015
C++11 introduced a new feature in the form of scoped enumerations, also
referred to as enum classes, since they are introduced with the double keyword
enum class (though enum struct is also permissible, to identical effect). To
a large extent, these are like standard enumerated types: you can declare a list
of enumerators, which you may assign explicit values to, or which you may let
the compiler assign values to. You can then assign these values to variables of
that type. However, they have additional properties which make them ideal for
use as bitfields. I recently answered a question on the accu-general mailing
list about such a use, so I thought it might be worth writing a blog post about
it.
Key features of scoped enumerations
The key features provided by scoped enumerations are:
- The enumerators must always be prefixed with the type name when referred to
outside the scope of the enumeration definition. e.g. for a scoped enumeration
colourwhich has an enumeratorgreen, this must be referred to ascolour::greenin the rest of the code. This avoids the problem of name clashes which can be common with plain enumerations. - The underlying type of the enumeration can be specified, to allow forward
declaration, and avoid surprising consequences of the compiler's choice. This
is also allowed for plain
enumin C++11. If no underlying type is specified for a scoped enumeration, the underlying type is fixed asint. The underlying type of a given enumeration can be found using thestd::underlying_typetemplate from the<type_traits>header. - There is no implicit conversion to and from the underlying type, though such a conversion can be done explicitly with a cast.
This means that they are ideal for cases where there is a limited set of values,
and there are several such cases in the C++ Standard itself: std::errc,
std::pointer_safety, and std::launch for example. The lack of implicit
conversions are particularly useful here, as it means that you cannot pass raw
integers such as 3 to a function expecting a scoped enumeration: you have to
pass a value of the enumeration, though this is of course true for unscoped
enumerations as well. The lack of implicit conversions to integers does mean
that you can overload a function taking a numeric type without having to worry
about any potential ambiguity due to numeric conversion orderings.
Bitmask types
Whereas the implicit conversions of plain enumerations mean that expressions
such as red | green and red & green are valid if red and green are
enumerators, the downside is that red * green or red / green are equally valid,
if nonsensical. With scoped enumerations, none of these expressions are valid
unless the relevant operators are defined, which means you can explicitly define
what you want to permit.
std::launch is a scoped enumeration that is also a bitmask type. This means
that expressions such as std::launch::async | std::launch::deferred and
std::launch::any & std::launch::async are valid, but you cannot multiply or
divide launch policies. The requirements on such a type are defined in section
17.5.2.1.3 [bitmask.types] of the C++ Standard, but they amount to providing
definitions for the operators |, &, ^, ~, |=, &= and ^= with the
expected semantics.
The implementation of these operators is trivial, so it is easy to create your own bitmask types, but having to actually define the operators for each bitmask type is undesirable.
Bitmask operator templates
These operators can be templates, so you could define a template for each operator, e.g.
template<typename E>
E operator|(E lhs,E rhs){
typedef typename std::underlying_type<E>::type underlying;
return static_cast<E>(
static_cast<underlying>(lhs) | static_cast<underlying>(rhs));
}Then you could write mask::x | mask::y for some enumeration mask with
enumerators x and y. The downside here is that it is too greedy: every type
will match this template. Not only would you would be able to write
std::errc::bad_message | std::errc::broken_pipe, which is clearly nonsensical,
but you would also be able to write "some string" | "some other string",
though this would give a compile error on the use of std::underlying_type,
since it is only defined for enumerations. There would also be potential clashes
with other overloads of operator|, such as the one for std::launch.
What is needed is a constrained template, so only those types which you want to support the operator will match.
SFINAE to the rescue
SFINAE is a term coined by David Vandevoorde and Nicolai Josuttis in their book C++ Templates: The Complete Guide. It stands for "Substitution Failure is Not an Error", and highlights a feature of expanding function templates during overload resolution: if substituting the template parameters into the function declaration fails to produce a valid declaration then the template is removed from the overload set without causing a compilation error.
This is a key feature used to constrain templates, both within the C++ Standard
Library, and in many other libraries and application code. It is such a key
feature that the C++ Standard Library even provides a library facility to assist
with its use: std::enable_if.
We can therefore use it to constain our template to just those scoped enumerations that we want to act as bitmasks.
template<typename E>
struct enable_bitmask_operators{
static constexpr bool enable=false;
};
template<typename E>
typename std::enable_if<enable_bitmask_operators<E>::enable,E>::type
operator|(E lhs,E rhs){
typedef typename std::underlying_type<E>::type underlying;
return static_cast<E>(
static_cast<underlying>(lhs) | static_cast<underlying>(rhs));
}If enable_bitmask_operators<E>::enable is false (which it is unless
specialized) then std::enable_if<enable_bitmask_operators<E>::enable,E>::type
will not exist, and so this operator| will be discarded without error. It will
thus not compete with other overloads of operator|, and the compilation will
fail if and only if there are no other matching
overloads. std::errc::bad_message | std::errc::broken_pipe will thus fail to
compile, whilst std::launch::async | std::launch::deferred will continue to
work.
For those types that we do want to work as bitmasks, we can then just specialize
enable_bitmask_opoerators:
enum class my_bitmask{
first=1,second=2,third=4
}:
template<>
struct enable_bitmask_operators<my_bitmask>{
static constexpr bool enable=true;
};Now, std::enable_if<enable_bitmask_operators<E>::enable,E>::type will exist
when E is my_bitmask, so this operator| will be considered by overload
resolution, and my_bitmask::first | my_bitmask::second will now compile.
Final code
The final code is available as a header file along with a simple example demonstrating its use. It has been tested with g++ 4.7, 4.8 and 4.9 in C++11 mode, and with MSVC 2012 and 2013, and is released under the Boost Software License.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++, enum, bitfields
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Copying Exceptions in C++0x
Tuesday, 15 March 2011
One of the new features of C++0x is the ability to capture
exceptions in a std::exception_ptr and rethrow them later
without knowing what type they are. This is particularly
useful, as it allows you to propagate the exceptions across threads
— you capture the exception in one thread, then pass the
std::exception_ptr object across to the other thread, and
then use std::rethrow_exception() on that other thread to
rethrow it. In fact, the exception propagation facilities
of std::async, std::promise
and std::packaged_task are build on this feature.
To copy or not to copy
The original proposal for the feature required that the exception
was copied when it was captured
with std::current_exception, but under pressure from
implementors that use
the "Itanium
ABI" (which is actually used for other platforms too, such as
64-bit x86 linux and MacOSX), the requirement was lessened to allow
reference counting the exceptions instead. The problem they cited
was that the ABI didn't store the copy constructor for exception
objects, so when you called std::current_exception()
the information required to copy the object was not present.
Race conditions
Unfortunately, no-one foresaw that this would open the door for race conditions, since the same exception object would be active on multiple threads at once. If any of the thread modified the object then there would be a data race, and undefined behaviour.
It is a common idiom to catch exceptions by non-const reference in
order to add further information to the exception, and then rethrow
it. If this exception came from another thread (e.g. through use
of std::async), then it may be active in multiple
threads at once if it was propagated
using std::shared_future, or even just
with std::exception_ptr directly. Modifying the
exception to add the additional information is thus a data race if
done unsynchronized, but even if you add a mutex to the class you're
still modifying an exception being used by another thread, which is
just wrong.
Race conditions are bad enough, but these race conditions are implementation-dependent. The draft allows for the exceptions to be copied (as originally intended), and some compilers do that (e.g. MSVC 2010), and it also allows for them to be reference counted, and other compilers do that (e.g. gcc 4.5 on linux). This means that code that is well-defined and race-condition-free on MSVC 2010 might be buggy, and have data races when compiled with gcc 4.5, but the compiler will not (and cannot) warn about it. This is the nastiest of circumstances — race conditions silently added to working code with no warning.
Dealing with the issue
BSI raised an issue on the FCD about this when it came to ballot time. This issue is GB-74, and thus must be dealt with one way or the other before the C++0x standard is published (though sadly, "being dealt with" can mean that it is rejected). This is being dealt with by LWG, so is also listed as LWG issue 1369, where there is a more complete proposed resolution. Unfortunately, we still need to convince the rest of the committee to make this change, including those implementors who use the Itanium ABI.
Extending the ABI
Fortunately, the Itanium ABI is designed to be extensible in a
backwards-compatible manner. This means that existing code compiled
with an existing compiler can be linked against new code compiled
with a new compiler, and everything "just works". The old code only
uses the facilities that existed when it was written, and the new
code takes advantage of the new facilities. This means that the
exception structures can be enhanced to add the necessary
information for copying the exception (the size of the object, so
we can allocate memory for it, and the address copy constructor, or
a flag to say "use memcpy".) This isn't quite perfect,
as exceptions thrown from old code won't have the new information,
but provided we can detect that scenario all is well, as the
standard draft allows us to throw std::bad_exception
in that case.
I have written a patch for gcc 4.5.0 which demonstrates this as a proof of concept.
This patch extends the exception structures as allowed by the ABI
to add two fields: one for the object size, and one for the copy
constructor. Exceptions thrown by old code will have a size of zero
(which is illegal, so acts as a flag for old code), and thus will be
captures as std::bad_exception when stored in
a std::exception_ptr. Trivially copyable objects such
as a plain int, or a POD class will have
a NULL copy constructor pointer but a valid size,
indicating that they are to be copied using memcpy.
To use the patch, get the sources for gcc 4.5.0 from your
local GCC mirror,
unpack them, and apply the patch. Then compile the patched sources
and install your new gcc somewhere. Now, when you compile code that
throws exceptions it will use the
new __cxa_throw_copyable function in place of the
old __cxa_throw function to store the requisite
information. Unless you link against the right support code then
your applications won't link; I found I had to use
the -static command line option to force the use of the
new exception-handling runtime rather than the standard platform
runtime.
/opt/newgcc/bin/g++ -std=c++0x -static foo.cpp -o foo
Note that if the copy constructor of the exception is not thread
safe then there might still be an issue when
using std::exception_ptr, as my patch doesn't include a
mutex. However, this would be an easy extension to make now the
proof of concept has been done. I also expect that there are cases
that don't behave quite right, as I am far from being an expert on
the gcc internals.
Hopefully, this proof of concept will help convince the rest of the C++ committee to accept GB-74 at the meeting in Madrid next week.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++, C++0x, WG21, Exceptions, Copying, exception_ptr, rethrow_exception
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
November 2010 C++ Standards Committee Mailing
Tuesday, 07 December 2010
The November 2010 mailing for the C++ Standards Committee was published last week. This is the post-meeting mailing for the November 2010 committee meeting.
As well as the usual core and library issues lists, this mailing also includes an updated summary of the status of the FCD comments, along with a whole host of papers attempting to address some the remaining FCD comments and a new C++0x working draft.
To move or not to move
In my blog post on the October mailing, I mentioned that the implicit generation of move constructors was a big issue. I even contributed a paper with proposed wording for removing implicit move generation from the draft — with expert core wording guidance from Jason Merrill, this became N3216. My paper was just to give the committee something concrete to vote on — it doesn't matter how good your arguments are; if there isn't a concrete proposal for wording changes then the committee can't vote on it. In the end, the decision was that implicit move generation was a good thing, even though there was the potential for breaking existing code. However, the conditions under which move operations are implicitly generated have been tightened: the accepted proposal was N3203: Tightening the conditions for generating implicit moves by Jens Maurer, which provides wording for Bjarne's paper N3201: Moving Right Along. The proposal effectively treats copy, move and destruction as a group: if you specify any of them manually then the compiler won't generate any move operations, and if you specify a move operation then the compiler won't generate a copy. For consistency and safety, it would have been nice to prevent implicit generation of copy operations under the same circumstances, but for backwards compatibility this is still done when it would be done under C++03, though this is deprecated if the user specifies a destructor or only one of the copy operations.
Exceptions and Destructors
The second big issue from the
October mailing was the issue of implicitly adding
noexcept to destructors. In the end, the committee went
for Jens Maurer's paper N3204:
Deducing "noexcept" for destructors — destructors have the
same exception specification they would have if they were implicitly
generated, unless the user explicitly says otherwise. This will break
code, but not much — the fraction of code that intentionally
throws an exception from a destructor is small, and easily annotated
with noexcept(false) to fix it.
Concurrency-related papers
There are 9 concurrency-related papers in this mailing, which I've summarised below. 8 of them were adopted at this meeting, and are now in the new C++0x working draft.
- N3188 - Revision to N3113: Async Launch Policies (CH 36)
This paper is a revision of N3113 from the August mailing. It is a minor revision to the previous paper, which clarifies and simplifies the proposed wording.
It provides a clearer basis for implementors to supply additional launch policies for
std::async, or for the committee to do so in a later revision of the C++ standard, by making thestd::launchenum a bitmask type. It also drops thestd::launch::anyenumeration value, and renamesstd::launch::synctostd::launch::deferred, as this better describes what it means.The use of a bitmask allows new values to be added which are either distinct values, or combinations of the others. The default policy for
std::asyncis thusstd::launch::async|std::launch::deferred.- N3191: C++ Timeout Specification
This paper is a revision of N3128: C++ Timeout Specification from the August mailing. It is a minor revision to the previous paper, which clarifies and simplifies the proposed wording.
There are several functions in the threading portion of the library that allow timeouts, such as the
try_lock_forandtry_lock_untilmember functions of the timed mutex types, and thewait_forandwait_untilmember functions of the future types. This paper clarifies what it means to wait for a specified duration (with the xxx_forfunctions), and what it means to wait until a specified time point (with the xxx_untilfunctions). In particular, it clarifies what can be expected of the implementation if the clock is changed during a wait.This paper also proposes replacing the old
std::chrono::monotonic_clockwith a newstd::chrono::steady_clock. Whereas the only constraint on the monotonic clock was that it never went backwards, the steady clock cannot be adjusted, and always ticks at a uniform rate. This fulfils the original intent of the monotonic clock, but provides a clearer specification and name. It is also tied into the new wait specifications, since waiting for a duration requires a steady clock for use as a basis.- N3192: Managing C++ Associated Asynchronous State
This paper is a revision of N3129: Managing C++ Associated Asynchronous State from the August mailing. It is a minor revision to the previous paper, which clarifies and simplifies the proposed wording.
This paper tidies up the wording of the functions and classes related to the future types, and clarifies the management of the associated asynchronous state which is used to communicate e.g. between a
std::promiseand astd::futurethat will receive the result.- N3193: Adjusting C++ Atomics for C Compatibility
This paper is an update to N3164: Adjusting C++ Atomics for C Compatibility from the October mailing.
It drops the C compatibility header
<stdatomic.h>, and the macro_Atomic, and loosens the requirements on theatomic_xxxtypes — they may be base classes of the associatedatomic<T>specializations, or typedefs to them.- N3194: Clarifying C++ Futures
This paper is a revision ofN3170: Clarifying C++ Futures from the October mailing.
There were a few FCD comments from the US about the use of futures; this paper outlines all the issues and potential solutions. The proposed changes are actually fairly minor though:
-
futuregains ashare()member function for easy conversion to the correspondingshared_futuretype; - Accessing a
shared_futurefor whichvalid()isfalseis now encouraged to throw an exception though it remains undefined behaviour; atomic_futureis to be removed;packaged_tasknow has avalid()member function instead ofoperator boolfor consistency with the future types.
A few minor changes have also been made to the wording to make things clearer.
-
- N3196: Omnibus Memory Model and Atomics Paper
This paper is an update to N3125: Omnibus Memory Model and Atomics Paper from the August mailing.
This paper clarifies the wording surrounding the memory model and atomic operations.
- N3197: Lockable Requirements for C++0x
This paper is an update to N3130: Lockable Requirements for C++0x from the October mailing. This is a minor revision reflecting discussions at Batavia.
This paper splits out the requirements for general lockable types away from the specific requirements on the standard mutex types. This allows the lockable concepts to be used to specify the requirements on a type to be used the the
std::lock_guardandstd::unique_lockclass templates, as well as for the various overloads of the wait functions onstd::condition_variable_any, without imposing the precise behaviour ofstd::mutexon user-defined mutex types.- N3209: Progress guarantees for C++0x (US 3 and US 186)(revised)
This paper is a revision ofN3152: Progress guarantees for C++0x (US 3 and US 186) from the October mailing. It is a minor revision to the previous paper, which extends the proposed wording to cover
compare_exchange_weakas well astry_lock.The FCD does not make any progress guarantees when multiple threads are used. In particular, writes made by one thread do not ever have to become visible to other threads, and threads aren't guaranteed ever to actually run at all. This paper looks at the issues and provides wording for minimal guarantees.
- N3230: Constexpr Library Additions: future
This paper has not yet been accepted by the committee. It adds constexpr to the default constructors of
futureandshared_future, so that they can be statically initialized.
Other adopted papers
Of course, the committee did more than just address implicit move, exceptions in destructors and concurrency. The full minutes are available as N3212 in the mailing. Here is a quick summary of some of the other changes made:
- Library functions that don't throw exceptions have been changed to
use
noexcept - The ratio arithmetic facilities have been changed to allow
libraries to try and give the correct result if the result is
representable, but the intermediate calculations may overflow
(e.g.
ratio_add<ratio<1,INTMAX_MAX>,ratio<1,INTMAX_MAX>>) (N3210) - New functions have been added to retrieve the current new handler, terminate handler or unexpected handler (N3189)
- Alignment control is now done with the
alignaskeyword, rather than an attribute (N3190) - Virtual function override control is now done with keywords
(including the first context sensitive keywords:
overrideamdfinal) rather than attributes (N3206)
For the remaining changes, see the full minutes.
FCD comment status
The count of unresolved FCD comments is dropping rapidly, and now stands at 75 (out of 564 total), of which only 56 have any technical content. See N3224: C++ FCD Comment Status from the mailing for the full list.
Your comments
If you have any opinions on any of the papers listed here, or the resolution of any NB comments, please add them to the comments for this post.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++0x, C++, standards, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy