Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive
ACCU 2016 - Concurrent Thinking
Friday, 15 April 2016
The ACCU 2016 conference is next week. The conference starts on Tuesday 19th April with the tutorial and workshop day and runs through to Saturday 23rd April.
I will be talking about "Concurrent Thinking" on the Saturday at 11:30am. This 90 minute session is a taster of my new 2-day workshop, which I will be running at NDC Oslo in June and CppCon in September.
Here's the abstract:
One of the most difficult issues around designing software with multiple threads of execution is synchronizing data.
Whether you use actors, active objects, futures and continuations or mutable shared state, every non-trivial system with multiple threads needs to transfer data between them. This means thinking about which data needs to be processed by which thread, and ensuring that the right data gets to the right threads in the right order. It also means thinking about API design to avoid race conditions.
In this presentation I’ll describe techniques we can use when doing this "thinking", as well as the tools we have available to help us describe our requirements and enforce them in code.
All examples will use C++, but the thought processes are widely applicable.
Hope to see you there!
Posted by Anthony Williams
[/ news /] permanent link
Tags: conferences, accu, C++, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Core C++ - lvalues and rvalues
Saturday, 27 February 2016
One of the most misunderstood aspect of C++ is the use of the terms lvalue and rvalue, and what they mean for how code is interpreted. Though lvalue and rvalue are inherited from C, with C++11, this taxonomy was extended and clarified, and 3 more terms were added: glvalue, xvalue and prvalue. In this article I'm going to examine these terms, and explain what they mean in practice.
Before we discuss the importance of whether something is an lvalue or rvalue, let's take a look at what makes an expression have each characteristic.
The Taxonomy
The result of every C++ expression is either an lvalue, or an rvalue. These terms come from C, but the C++ definitions have evolved quite a lot since then, due to the greater expressiveness of the C++ language.
rvalues can be split into two subcategories: xvalues, and prvalues, depending on the details of the expression. These subcategories have slightly different properties, described below.
One of the differences is that xvalues can sometimes be treated the same as lvalues. To cover those cases we have the term glvalue — if something applies to both lvalues and xvalues then it is described as applying to glvalues.
Now for the definitions.
glvalues
A glvalue is a Generalized lvalue. It is used to refer to something that could be either an lvalue or an xvalue.
rvalues
The term rvalue is inherited from C, where rvalues are things that can be on the Right side of an assignment. The term rvalue can refer to things that are either xvalues or prvalues.
lvalues
The term lvalue is inherited from C, where lvalues are things that can be on the Left side of an assignment.
The simplest form of lvalue expression is the name of a variable. Given a variable declaration:
A v1;
The expression v1 is an lvalue of type A.
Any expression that results in an lvalue reference (declared with &) is also
an lvalue, so the result of dereferencing a pointer, or calling a function
that returns an lvalue reference is also an lvalue. Given the following
declarations:
A* p1;
A& r1=v1;
A& f1();
The expression *p1 is an lvalue of type A, as is the expression f1() and
the expression r1.
Accessing a member of an object where the object expression is an lvalue is also an lvalue. Thus, accessing members of variables and members of objects accessed through pointers or references yields lvalues. Given
struct B{
A a;
A b;
};
B& f2();
B* p2;
B v2;then f2().a, p2->b and v2.a are all lvalues of type A.
String literals are lvalues, so "hello" is an lvalue of type array of 6
const chars (including the null terminator). This is distinct from other
literals, which are prvalues.
Finally, a named object declared with an rvalue reference (declared with &&)
is also an lvalue. This is probably the most confusing of the rules, if for no
other reason than that it is called an rvalue reference. The name is just
there to indicate that it can bind to an rvalue (see later); once you've
declared a variable and given it a name it's an lvalue. This is most commonly
encountered in function parameters. For example:
void foo(A&& a){
}Within foo, a is an lvalue (of type A), but it will only bind to rvalues.
xvalues
An xvalue is an eXpiring value: an unnamed objects that is soon to be destroyed. xvalues may be either treated as glvalues or as rvalues depending on context.
xvalues are slightly unusual in that they usually only arise through explicit
casts and function calls. If an expression is cast to an rvalue reference to
some type T then the result is an xvalue of type
T. e.g. static_cast<A&&>(v1) yields an xvalue of type A.
Similarly, if the return type of a function is an rvalue reference to some
type T then the result is an xvalue of type T. This is the case with
std::move(), which is declared as:
template <typename T>
constexpr remove_reference_t<T>&&
move(T&& t) noexcept;Thus std::move(v1) is an xvalue of type A — in this case, the type
deduction rules deduce T to be A& since v1 is an lvalue, so
the return type is declared to be A&& as remove_reference_t<A&> is just A.
The only other way to get an xvalue is by accessing a member of an
rvalue. Thus expressions that access members of temporary objects
yield xvalues, and the expression B().a is an xvalue of type A, since
the temporary object B() is a prvalue. Similarly,
std::move(v2).a is an xvalue, because std::move(v2) is an xvalue, and
thus an rvalue.
prvalues
A prvalue is a Pure rvalue; an rvalue that is not an xvalue.
Literals other than string literals (which are lvalues) are
prvalues. So 42 is a prvalue of type int, and 3.141f is a prvalue
of type float.
Temporaries are also prvalues. Thus given the definition of A above, the
expression A() is a prvalue of type A. This applies to all temporaries:
any temporaries created as a result of implicit conversions are thus also
prvalues. You can therefore write the following:
int consume_string(std::string&& s);
int i=consume_string("hello");as the string literal "hello" will implicitly convert to a temporary of type
std:string, which can then bind to the rvalue reference used for the
function parameter, because the temporary is a prvalue.
Reference binding
Probably the biggest difference between lvalues and rvalues is in how they bind to references, though the differences in the type deduction rules can have a big impact too.
There are two types of references in C++: lvalue references, which are
declared with a single ampersand, e.g. T&, and rvalue references which are
declared with a double ampersand, e.g. T&&.
lvalue references
A non-const lvalue reference will only bind to non-const
lvalues of the same type, or a class derived from the referenced
type.
struct C:A{};
int i=42;
A a;
B b;
C c;
const A ca{};
A& r1=a;
A& r2=c;
//A& r3=b; // error, wrong type
int& r4=i;
// int& r5=42; // error, cannot bind rvalue
//A& r6=ca; // error, cannot bind const object to non const ref
A& r7=r1;
// A& r8=A(); // error, cannot bind rvalue
// A& r9=B().a; // error, cannot bind rvalue
// A& r10=C(); // error, cannot bind rvalueA const lvalue reference on the other hand will also bind to
rvalues, though again the object bound to the reference must have
the same type as the referenced type, or a class derived from the referenced
type. You can bind both const and non-const values to a const lvalue
reference.
const A& cr1=a;
const A& cr2=c;
//const A& cr3=b; // error, wrong type
const int& cr4=i;
const int& cr5=42; // rvalue can bind OK
const A& cr6=ca; // OK, can bind const object to const ref
const A& cr7=cr1;
const A& cr8=A(); // OK, can bind rvalue
const A& cr9=B().a; // OK, can bind rvalue
const A& cr10=C(); // OK, can bind rvalue
const A& cr11=r1;If you bind a temporary object (which is a prvalue) to a const
lvalue reference, then the lifetime of that temporary is extended to the
lifetime of the reference. This means that it is OK to use r8, r9 and r10
later in the code, without running the undefined behaviour that would otherwise
accompany an access to a destroyed object.
This lifetime extension does not extend to references initialized from the first
reference, so if a function parameter is a const lvalue reference, and gets bound
to a temporary passed to the function call, then the temporary is destroyed when
the function returns, even if the reference was stored in a longer-lived
variable, such as a member of a newly constructed object. You therefore need to
take care when dealing with const lvalue references to ensure that you
cannot end up with a dangling reference to a destroyed temporary.
volatile and const volatile lvalue references are much less interesting,
as volatile is a rarely-used qualifier. However, they essentially behave as
expected: volatile T& will bind to a volatile or non-volatile, non-const
lvalue of type T or a class derived from T, and volatile const T& will bind to any lvalue of type T or a class derived from
T. Note that volatile const lvalue references do not bind to rvalues.
rvalue references
An rvalue reference will only bind to rvalues of the same
type, or a class derived from the referenced type. As for lvalue references,
the reference must be const in order to bind to a const object, though
const rvalue references are much rarer than const lvalue references.
const A make_const_A();
// A&& rr1=a; // error, cannot bind lvalue to rvalue reference
A&& rr2=A();
//A&& rr3=B(); // error, wrong type
//int&& rr4=i; // error, cannot bind lvalue
int&& rr5=42;
//A&& rr6=make_const_A(); // error, cannot bind const object to non const ref
const A&& rr7=A();
const A&& rr8=make_const_A();
A&& rr9=B().a;
A&& rr10=C();
A&& rr11=std::move(a); // std::move returns an rvalue
// A&& rr12=rr11; // error rvalue references are lvaluesrvalue references extend the lifetime of temporary objects in the same way
that const lvalue references do, so the temporaries associated with rr2,
rr5, rr7, rr8, rr9, and rr10 will remain alive until the
corresponding references are destroyed.
Implicit conversions
Just because a reference won't bind directly to the value of an expression, doesn't mean you can't initialize it with that expression, if there is an implicit conversion between the types involved.
For example, if you try and initialize a reference-to-A with a D object, and
D has an implicit conversion operator that returns an A& then all is well,
even though the D object itself cannot bind to the reference: the reference is
bound to the result of the conversion operator.
struct D{
A a;
operator A&() {
return a;
}
};
D d;
A& r=d; // reference bound to result of d.operator A&()Similarly, a const lvalue-reference-to-E will bind to an A object if A
is implicitly convertible to E, such as with a conversion constructor. In this
case, the reference is bound to the temporary E object that results from the
conversion (which therefore has its lifetime extended to match that of the
reference).
struct E{
E(A){}
};
const E& r=A(); // reference bound to temporary constructed with E(A())This allows you to pass string literals to functions taking std::string by
const reference:
void foo(std::string const&);
foo("hello"); // ok, reference is bound to temporary std::string objectOther Properties
Whether or not an expression is an lvalue or rvalue can affect a few other aspects of your program. These are briefly summarised here, but the details are out of scope of this article.
In general, rvalues cannot be modified, nor can they have their
address taken. This means that simple expressions like A()=something or &A()
or &42 are ill-formed. However, you can call member functions on
rvalues of class type, so X().do_something() is valid (assuming
class X has a member function do_something).
Class member functions can be tagged with ref qualifiers to indicate that they
can be applied to only rvalues or only lvalues. ref
qualifiers can be combined with const, and can be used to distinguish
overloads, so you can define different implementations of a function depending
whether the object is an lvalue or rvalue.
When the type of a variable or function template parameter is deduce from its initializer, whether the initializer is an lvalue or rvalue can affect the deduced type.
End Note
rvalues and lvalues are a core part of C++, so understanding them is essential. Hopefully, this article has given you a greater understanding of their properties, and how they relate to the rest of C++.
If you liked this article, please share with the buttons below. If you have any questions or comments, please submit them using the comment form.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, lvalues, rvalues
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++ Concurrency in Action now available in Chinese!
Wednesday, 03 February 2016

Last week there was considerable excitement in my house as I received my copies of the Chinese translation of my book. The code looks the same, and they spelled my name correctly, but that's all I can tell. I can't read a word of Chinese, so I hope the content has translated OK, and doesn't read like it's been run through automatic translation software.
It's a great feeling to know that my book is going to reach a wider audience, joining the ranks of the C++ books available in Chinese. As Bjarne commented when I posted on Facebook, "we are getting there".
Posted by Anthony Williams
[/ news /] permanent link
Tags: C++, concurrency, multithreading, book
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
CppCast Interview
Wednesday, 07 October 2015
I was pleasantly surprised when Rob and Jason from CppCast approached me to be a guest on their podcast, to talk about concurrency in C++11 and C++14. The recording went live last week.
We had a brief discussion about the C++ Core Guidelines introduced by Bjarne Stroustrup and Herb Sutter at this year's CppCon, and the Guideline Support Library (GSL) that accompanies it, before moving on to the concurrency discussion.
As well as the C++11 and C++14 threading facilities, I also talked about the Parallelism TS, which has been officially published, and the Concurrency TS, which is still being worked on.
I always enjoy talking about concurrency, and this was no exception. I hope you enjoy listening.
Posted by Anthony Williams
[/ news /] permanent link
Tags: cppcast, interview, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
just::thread C++11 and C++14 Thread Library V2.2 released
Wednesday, 30 September 2015
I am pleased to announce that version 2.2 of
just::thread, our C++11 and C++14 Thread Library
has just been released with full support for the latest draft of the Concurrency
TS, and support for Microsoft Visual Studio 2015.
New features
New facilities from the Concurrency TS:
- A lock-free implementation of
atomic_shared_ptrandatomic_weak_ptr— see my earlier blog post onatomic_shared_ptr - Latches — signal waiting threads once a specified number of count-down events have occurred.
- Barriers — block a group of threads until they are all ready to proceed.
future::then()— schedule a task to run when a future becomes ready.when_any()— create a future that is ready when any of a set of futures is ready.when_all()— create a future that is ready when all of a set of futures are ready.
Also:
jss::joining_thread— a simple wrapper aroundstd::threadthat always joins in its destructor.
Supported compilers
Just::Thread is now supported for the following compilers:
- Microsoft Windows XP and later:
- Microsoft Visual Studio 2005, 2008, 2010, 2012, 2013 and 2015
- TDM gcc 4.5.2, 4.6.1 and 4.8.1
- Debian and Ubuntu linux (Ubuntu Jaunty and later)
- g++ 4.3, 4.4, 4.5, 4.6, 4.7, 4.8 and 4.9
- Fedora linux
- Fedora 13: g++ 4.4
- Fedora 14: g++ 4.5
- Fedora 15: g++ 4.6
- Fedora 16: g++ 4.6
- Fedora 17: g++ 4.7.2 or later
- Fedora 18: g++ 4.7.2 or later
- Fedora 19: g++ 4.8
- Fedora 20: g++ 4.8
- Fedora 21: g++ 4.9
- Intel x86 MacOSX Snow Leopard or later
- MacPorts g++ 4.3, 4.4, 4.5, 4.6, 4.7 and 4.8
Get your copy of Just::Thread
Purchase your copy and get started with the C++11 and C++14 thread library now.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x, C++11, C++14
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Core C++ - Destructors and RAII
Thursday, 24 September 2015
Though I love many features of C++, the feature that I think is probably the most important for writing robust code is deterministic destruction and destructors.
The destructor for an object is called when that object is destroyed, whether explicitly with the delete operator, or implicitly when it goes out of scope. This provides an opportunity to clean up any resources held by that object, thus making it easy to avoid leaking memory, or indeed any kind of resource.
This has led to the idiom commonly known as Resource Acquisition Is Initialization (RAII) — a class acquires some resource when it is initialised (in its constructor), and then releases it in its destructor. A better acronym would be DIRR — Destruction Is Resource Release — as the release in the destructor is the important part, but RAII is what has stuck.
The power of RAII
This is incredibly powerful, and makes it so much easier to write robust
code. It doesn't matter how the object goes out of scope, whether it is due to
just reaching the end of the block, or due to a control transfer statement such
as goto, break or continue, or because the function has returned, or
because an exception is thrown. However the object is destroyed, the destructor
is run.
This means you don't have to litter your code with calls to cleanup functions. You just write a class to manage a resource and have the destructor call the cleanup function. Then you can just create objects of that type and know that the resource will be correctly cleaned up when the object is destroyed.
No more leaks
If you don't use resource management classes, it can be hard to ensure that your resources are correctly released on all code paths, especially in the presence of exceptions. Even without exceptions, it's easy to fail to release a resource on a rarely-executed code path. How many programs have you seen with memory leaks?
Writing a resource management class for a particular resource is really easy,
and there are many already written for you. The C++ standard is full of
them. There are the obvious ones like std::unique_ptr and std::shared_ptr
for managing heap-allocated objects, and std::lock_guard for managing lock
ownership, but also std::fstream and std::file_buf for managing file
handles, and of course all the container types.
I like to use std::vector<char> as a generic buffer-management class for
handling buffers for legacy C-style APIs. The always-contiguous guarantee means
that it's great for anything that needs a char buffer, and there is no messing
around with reallocor the potential for buffer overrun you get with fixed-size
buffers.
For example, many Windows API calls take a buffer in which they return the
result, as well as a length parameter to specify how big the buffer is. If the
buffer isn't big enough, they return the required buffer size. We can use this
with std::vector<char> to ensure that our buffer is big enough. For example,
the following code retrieves the full path name for a given relative path,
without requiring any knowledge about how much space is required beforehand:
std::string get_full_path_name(std::string const& relative_path){
DWORD const required_size=GetFullPathName(relative_path.c_str(),0,NULL,&filePart);
std::vector<char> buffer(required_size);
if(!GetFullPathName(relative_path.c_str(),buffer.size(),buffer.data(),&filePart))
throw std::runtime_error("Unable to retrieve full path name");
return std::string(buffer.data());
}Nowhere do we need to explicitly free the buffer: the destructor takes care of that for us, whether we return successfully or throw. Writing resource management classes enables us to extend this to every type of resource: no more leaks!
Writing resource management classes
A basic resource management class needs just two things: a constructor that takes ownership of the resource, and a destructor that releases ownership. Unless you need to transfer ownership of your resource between scopes you will also want to prevent copying or moving of your class.
class my_resource_handle{
public:
my_resource_handle(...){
// acquire resource
}
~my_resource_handle(){
// release resource
}
my_resource_handle(my_resource_handle const&)=delete;
my_resource_handle& operator=(my_resource_handle const&)=delete;
};Sometimes the resource ownership might be represented by some kind of token,
such as a file handle, whereas in other cases it might be more conceptual, like
a mutex lock. Whatever the case, you need to store enough data in your class to
ensure that you can release the resource in the destructor. Sometimes you might
want your class to take ownership of a resource acquired elsewhere. In this
case, you can provide a constructor to do that. std::lock_guard is a nice
example of a resource-ownership class that manages an ephemeral resource, and
can optionally take ownership of a resource acquired elsewhere. It just holds a
reference to the lockable object being locked and unlocked; the ownership of the
lock is implicit. The first constructor always acquires the lock itself, whereas
the second constructor taking an adopt_lock_t parameter allows it to take
ownership of a lock acquired elsewhere.
template<typename Lockable>
class lock_guard{
Lockable& lockable;
public:
explicit lock_guard(Lockable& lockable_):
lockable(lockable_){
lockable.lock();
}
explicit lock_guard(Lockable& lockable_,adopt_lock_t):
lockable(lockable_){}
~lock_guard(){
lockable.unlock();
}
lock_guard(lock_guard const&)=delete;
lock_guard& operator=(lock_guard const&)=delete;
};Using std::lock_guard to manage your mutex locks means you no longer have to
worry about ensuring that your mutexes are unlocked when you exit a function:
this just happens automatically, which is not only easy to manage conceptually,
but less typing too.
Here is another simple example: a class that saves the state of a Windows GDI DC, such as the current pen, font and colours.
class dc_saver{
HDC dc;
int state;
public:
dc_saver(HDC dc_):
dc(dc_),state(SaveDC(dc)){
if(!state)
throw std::runtime_error("Unable to save DC state");
}
~dc_saver(){
RestoreDC(dc,state);
}
dc_saver(dc_saver const&)=delete;
dc_saver& operator=(dc_saver const&)=delete;
};You could use this as part of some drawing to save the state of the DC before changing it for local use, such as setting a new font or new pen colour. This way, you know that whatever the state of the DC was when you started your function, it will be safely restored when you exit, even if you exit via an exception, or you have multiple return points in your code.
void draw_something(HDC dc){
dc_saver guard(dc);
// set pen, font etc.
// do drawing
} // DC properties are always restored hereAs you can see from these examples, the resource being managed could be anything: a file handle, a database connection handle, a lock, a saved graphics state, anything.
Transfer season
Sometimes you want to transfer ownership of the resource between scopes. The classical use case for this is you have some kind of factory function that acquires the resource and then returns a handle to the caller. If you make your resource management class movable then you can still benefit from the guaranteed leak protection. Indeed, you can build it in at the source: if your factory returns an instance of your resource management rather than a raw handle then you are protected from the start. If you never expose the raw handle, but instead provide additional functions in the resource management class to interact with it, then you are guaranteed that your resource will not leak.
std::async provides us with a nice example of this in action. When you start a
task with std::async, then you get back a std::future object that references
the shared state. If your task is running asynchronously, then the destructor
for the future object will wait for the task to complete. You can, however, wait
explicitly beforehand, or return the std::future to the caller of your
function in order to transfer ownership of the "resource": the running
asynchronous task.
You can add such ownership-transfer facilities to your own resource management classes without much hassle, but you need to ensure that you don't end up with multiple objects thinking they own the same resource, or resources not being released due to mistakes in the transfer code. This is why we start with non-copyable and non-movable classes by deleting the copy operations: then you can't accidentally end up with botched ownership transfer, you have to write it explicitly, so you can ensure you get it right.
The key part is to ensure that not only does the new instance that is taking ownership of the resource hold the proper details to release it, but the old instance will no longer try and release the resource: double-frees can be just as bad as leaks.
std::unique_lock is the big brother of std::lock_guard that allows transfer
of ownership. It also has a bunch of additional member functions for acquiring
and releasing locks, but we're going to focus on just the move semantics. Note:
it is still not copyable: only one object can own a given lock, but we can
change which object that is.
template<typename Lockable>
class unique_lock{
Lockable* lockable;
public:
explicit unique_lock(Lockable& lockable_):
lockable(&lockable_){
lockable->lock();
}
explicit unique_lock(Lockable& lockable_,adopt_lock_t):
lockable(&lockable_){}
~unique_lock(){
if(lockable)
lockable->unlock();
}
unique_lock(unique_lock && other):
lockable(other.lockable){
other.lockable=nullptr;
}
unique_lock& operator=(unique_lock && other){
unique_lock temp(std::move(other));
std::swap(lockable,temp.lockable);
return *this;
}
unique_lock(unique_lock const&)=delete;
unique_lock& operator=(unique_lock const&)=delete;
};Firstly, see how in order to allow the assignment, we have to hold a pointer to
the Lockable object rather than a reference, and in the destructor we have to
check whether or not the pointer is nullptr. Secondly, see that in the move
constructor we explicitly set the pointer to nullptrfor the source of our
move, so that the source will no longer try and release the lock in its
destructor.
Finally, look at the move-assignment operator. We have explicitly transferred
ownership from the source object into a new temporary object, and then swapped
the resources owned by the target object and our temporary. This ensures that
when the temporary goes out of scope, its destructor will release the lock
owned by our target beforehand, if there was one. This is a common pattern among
resource management classes that allow ownership transfer, as it keeps
everything tidy without having to explicitly write the resource cleanup code in
more than one place. If you've written a swap function for your class then you
might well use that here rather than directly exchanging the members, to avoid
duplication.
Wrapping up
Using resource management classes can simplify your code, and reduce the need for debugging, so use RAII for all your resources to avoid leaks and other resource management issues. There are many classes already provided in the C++ Standard Library or third-party libraries, but it is trivial to write your own resource management wrapper for any resource if there is a well-defined API for acquiring and releasing the resource.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, destructors, RAII
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Agile on the Beach Conference Report
Tuesday, 15 September 2015

The Agile On The Beach 2015 conference took place last week, on 3rd/4th September. It was hosted at the Performance Centre at the Tremough campus of Falmouth University and the University of Exeter, near Falmouth, Cornwall, UK.
The conference featured 48 sessions over the 2 days, with 5 tracks running on the Thursday and 4 tracks running on the Friday. Topics covered everything from estimating, project management, and implementing agile to source control, testing practices, and teaching software developers.
What follows is a summary of the sessions I attended. Slides and videos of all the talks should be available from the Agile On The Beach website in due course.
Farley's 3 laws
The opening keynote was Dave Farley, coauthor of Continuous Delivery. Rather than talk to us about continuous delivery, he introduced Farley's 3 laws:
- People are crap
- Stuff is more complicated than you think
- All stuff is interesting (if you look at it in the right way)
People are slow, lazy and unobservant. Thinking requires real effort, measurable in brain scans, so we are hard-wired to avoid it where possible, making snap judgements and guesses. Our eyes cannot take in a whole scene at once, so they scan around, and our brain fills in the areas we're not looking at for that millisecond with what it thinks is likely based on what was there when we last looked in that direction.
The best indicator for whether or not people will agree with you in a meeting is how good the food was: feed people well and they will look favourably on you and your suggestions.
Our brain is a pattern-recognition engine. If we can recognize a pattern then we don't need to consciously think about the details. This has some surprising consequences, such as that we can hear speech in a simple set of sine waves. Dave played us some audio files of sine waves, then someone talking, and then the sine waves again: we could all hear the speech in the second set of sine waves. He also showed us various optical illusions, with static images that appear to move, black and white images that appear in colour and so forth.
By being aware of our tendencies to be lazy, and jump to conclusions we can consciously decide to pay attention to how things are. Apply the scientific method: hypothesize, test, repeat. This is the core of Agile and Lean, and the manufacturing ideas of Dr W. Edwards Demming, and it's how we managed to get a man on the moon in 1969 despite barely any of the technology existing when President Kennedy suggested the idea.
- Don't do things because we've always done them that way,
- Don't start work on a guess or jump to conclusions,
- Don't be afraid of failure,
- Question everything,
- Always think "how can I test this?",
- Iterate to learn and adapt.
Remember: everything is interesting.
ClojureScript
After the break, Jim Barritt was presenting a live demo of ClojureScript. This is essentially just a Clojure-to-JavaScript compiler, which allows you to write Web applications in Clojure.
One particularly neat aspect is the way that it integrates with the server side code, so you can have Clojure code running both on the server and in the browser.
Another nice feature is that error messages in the browser console refer directly to the line in the ClojureScript file that the JavaScript was generated from, rather than a line in the generated JavaScript.
Test-driving User Interfaces
Next up was my presentation on Test-driving User Interfaces. The main thrust of my presentation is that in principle User Interfaces are no harder to test-drive than any other bit of code, we just need to know how.
Also, desktop frameworks don't tend to support testing UIs, so we need to develop our own library of support code to drive the UI from within our tests.
After my presentation it was time for lunch.
Only You can Analyze the Code
What happens if only one member of the team is allowed to run static analysis tools on a codebase? That is the question that Anna-Jayne Metcalfe's talk was there to answer after lunch.
As you might guess, the answer is not good. Though it can be nice to get a heads-up on the state of your code base, this is all you really get if only one person does it. To get the most out of static analysis tools you need to have the whole team involved, and have the analysis run before check-in.
On a large legacy code base you might well end up with several lint warnings per line for you crank up the analysis level too much. Wading through millions of messages to find the important ones is not for the faint-hearted. Better is to set the warning level to a minimum, so only the nastiest issues get flagged. If you run the analysis locally, before check-in, you have a chance to fix things before the code gets committed.
If you're going to do Scrum, do it right
That was the message of Amy Thompson's talk "Scrum ... Really?". This was more of a pep-talk selling the benefits of doing Scrum by the book than a "how-to", but there were titbits of real advice in there on things you should be doing:
- Scrum needs proper buy-in at all levels of management
- Have a physical progress board, so everyone can see the state of the project
- The Product Owner needs to work on the stories before adding them to the backlog to provide a clear definition of done
Don't let your organization do "Scrum, but ...".
Use contract tests to ease integration pain
The penultimate talk of the first day was Stefan Smith's talk titled "Escape the integration syrup with contract tests". If your software is part of an ecosystem of cooperating pieces of software then you need to ensure that everything works together. This is the role of integration tests.
However, if each piece of the ecosystem has its own release schedule then this can make integration difficult. Organizations typically wrap a combination of builds of the individual components into a single monolithic system build for integration testing, which then moves through the various test stages as a package.
If you're trying to release a small change to one of the components this can cause a big delay, as your change has to join the next release train.
Contract tests can help. Each component carries with it tests for the required behaviour of all the components it interacts with. These are packaged alongside the component, and come in two parts: a test client that mimics the behaviour of this component and the way it uses other components, and a dummy server that provides a minimal test-double that demonstrates the required behaviour.
When testing the component itself, you run it against the test-double. You also need to run the test-client against the test-double to ensure that you keep your behaviour in sync. When testing interactions between components you run the test-client from one against the real implementation of the other, and vice-versa.
Since these test-clients embody the interface to the component, they allow you to test whether components work together without having to do full integration tests. If component A is used by components B and C, when developing component A version 57, you can run it against the contract tests for all the versions of components B and C in the release pipeline. If all the contract tests pass, you may then be able to bring this new release forward to the pre-production staging area for final integration tests without having to go through the full pipeline.
Done right, this can save a lot of pain and allow faster deployment of individual components. However, this is not free. You have to pay attention to ensure the contract tests are properly updated, and there can be many combinations to run, which requires time and resources.
Mob rule
"Product Development in an Unruly Mob" was the title of the final talk I attended on the first day. Benji Weber and Alex Wilson from Unruly spoke about a practice they use called "Mob Programming". This is pair programming taken a step further, so the whole team sits in a "mob" around a single computer, rather than each person doing their own thing.
You need a large screen so everyone can see — they use a 50" TV — as well as a smaller screen for the person at the keyboard to use.
One important point is that the person at the keyboard should not do anything that has not been decided by the group as a whole. This makes it possible for non-programmers to drive. They also suggest that you need to change the driver frequently so everyone on the team gets a turn relatively often, and everyone feels involved.
They commented that the closest they've ever got to an "ideal programming day" was when mob programming.
They don't mob all the time; sometimes people will peel off the mob to take a break, or to work on something that really is a single-person task. However, they try to eliminate the need for such single-person tasks.
Their experience has shown that mob programming can help eliminate the common team dysfunctions: it builds trust, as you're all there together, it reduces conflict because everyone can get heard, and it builds commitment and accountability as the whole team is there and everything is decided together.
Party!!!
The first day ended with a party on the beach. This was a great opportunity to have discussions with people about the day's talks, as well as to discuss wider issues around software development and life.
Day 2
The second day of the conference was just as good as the first. I missed out on watching any of the sessions in one of the afternoon slots due to having extended discussions in the break, but that's the way things go — the discussions with other delegates are probably more valuable than the sessions themselves anyway.
Agile Leadership
The Friday morning keynote was by Jenni Jepsen, on "Agile Leadership and Teams".
Agile works because the processes support the reward mechanisms in the brain; the neuroscience proves that Agile works.
We work best when we have moderate levels of stress hormones. Too much stress and our brain shuts down and performance suffers. Likewise for too little, but that's not a common concern in the workplace. If you're over-stressed then support and encouragement can help reduce stress, and improve performance. The collaboration techniques in Agile methodologies have this effect.
Our brains are great at pattern matching, so we can manage to read sentences with all the letters in each word scrambled, provided the first and last letters of each word are correct.
If we have a feeling of control, our Pre-Frontal Cortex functions better, and can override the stress response from our limbic system.
If we're stressed for 2 weeks we can become more negative as our brain is rewired. We then need 2 weeks of no-stress to recover. By focusing on positive things then our brain is rewired in a positive fashion.
Agile processes help with providing us these positive things:
- Craftsmanship and pride in what we're doing
- Certainty, having an overview of what's coming next. Planning for uncertainty creates certainty in the brain: we're certain things are going to change
- Influence and autonomy: we plan the details ourselves in our teams, rather than having things imposed from above
- Connection with people, by working in teams
Focusing on relationships before tasks helps us get to the tasks quicker, and do the tasks better.
Taking Back BDD
Next up was Konstantin Kudryashov, with the first of the two talks I attended on Behaviour Driven Development (BDD).
One of the central aspects of BDD is the structure of the BDD tests: Given a setup, when I do something, then the outcome is this. Konstantin wants us to really drill down in these scenarios, and use them as a focus for a conversation with the customer. This can really help us build our ubiquitous language, and help with Domain Driven Design (DDD).
Konstantin used an example of an application to help conference delegates plan which talks they are going to attend. This was something we could all relate to, since the conference organisers were plugging the use of the free Whova app for doing exactly this.
"Given that there's a conference 'Agile on the Beach', and that the first session in track 1 on Friday is 'Taking Back BDD' ..."
Talk to the customer: what do we mean "there's a conference 'Agile on the Beach'"? What do we mean by "session"? What do we mean by "track 1"?
Each of these questions can help us flesh out our scenario, and help drive the interface of our domain objects. Create factory functions that mimic the structure of the sentence:
$conference=Conference::namedWithTracks("Agile on the Beach",5);BDD drives the conversations that help us build the ubiquitous language for our DDD. This leads to fewer misunderstandings, as the customer, the programmer and the code all use the same terms for the same things, which leads to happier customers.
Watching Konstantin made me think "I really ought to do this on my projects".
10 things you need to know about BDD
The second BDD talk was in the very next slot. This one was presented by Seb Rose. He first provided 10 (base 12) things you need to know about BDD, which he reduced to 10 (base 2) things you need to know at the end.
Fundamentally, BDD is about collaboration and conversations between the developers, testers and customers. Tools like Cucumber and Specflow provide nice ways of automating the test scenarios that arise from the conversations, but you don't need them to make it work.
Code Club : Creating the next generation of software developers
After lunch, Mike Trebilcock spoke with enthusiasm about what we can do to encourage young people to get interested in software development.
Mike used the metaphor of a "pipeline" to anchor his talk, with key markers at the various stages of education from primary school onwards, culminating in a career in software development. This is a "leaky" pipeline: not everyone from every stage will continue to have an interest in software development at the next stage.
Mike wants us to work to cultivate interest in children at primary school, and then keep that interest all through education, to ensure we have a new generation of skilled software developers. He encouraged us to help with or start Code Clubs, and to work with schools and colleges on their curriculum to ensure that they are teaching the things we as an industry would find valuable.
Cornwall College and Falmouth University have new degree courses on game development and software development. The software development course in particular has been developed in association with Software Cornwall to provide the skills that would be useful for local software companies.
All of us can help teach and encourage the next generation of programmers.
Financial Prioritization
Antonello Nardini's presentation hinged on a single premise: if we can estimate the actual monetary business value and cost of our stories, then we can use that information to aid in prioritization, and thus help our customers get more money sooner, or maintain cashflow.
Sadly, there was nothing in this that wasn't covered in Mike Cohn's Agile Estimating and Planning. Also, I find the premise to be flawed: it is rare to be able to predict with any certainty what the monetary value of a feature is likely to be. Doing fancy calculations such as Internal Rate of Return on estimated values just compounds the uncertainty, and gives you numbers that look good, but are basically useless.
I tried asking Antonello how he dealt with this in practice, but didn't come away with anything I could use: "it depends". I won't be trying to use financial prioritization of my projects.
What is Agile?
Woody Zuill presented the conference Endnote. He started by talking to us about the Agile Manifesto: what does it mean? What does "over" mean in this context?
He likes to think of it like "I value being fit and healthy OVER eating junk food". It doesn't mean that eating junk food is ruled out per se, but you try not to do it, especially not to the point that it stops you being fit and healthy.
Woody reminded us of John Gall's writing: complex systems that work invariably have come from simple systems that work, so start there, don't go straight for a big complex system.
You might not even need the whole system that you first envisaged. Woody tells the story of a project he worked on where there were 12 calculations that the business wanted automating to improve their production. Doing all 12 would have been a big complex task, so Woody's team started with the one calculation that was most vital to automate. When this was done, working and released, they worked on the others one at a time. After the 4th was done, the business said "that's enough" — we don't need the others done after all, they're not that valuable. If they'd started doing a system for all 12 calculations then it would have been much more complex, much more expensive, and would have done a load of work that ultimately the customer didn't actually need.
Woody sums up this approach with "Deliver features until bored" — keep delivering features until the customer is bored, and doesn't want to invest any more in the product.
I'll be back
Agile on the Beach 2015 was a great conference, and I'll be back next year. The question is: will you? Mega early bird tickets for 2016 are already on sale.
Posted by Anthony Williams
[/ news /] permanent link
Tags: agile, agileotb, conference
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Slides for my Test Driving User Interfaces Presentation
Friday, 04 September 2015
I presented my talk on Test Driving User Interfaces at Agile On The Beach yesterday. It was reasonably well attended and there were some interesting questions from the audience.
Here are my slides in case you missed it, or just wanted to remind yourself of what they said.
Posted by Anthony Williams
[/ news /] permanent link
Tags: agilotb, tdd, ui
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Why do we need atomic_shared_ptr?
Friday, 21 August 2015
One of the new class templates provided in the upcoming
Concurrency TS
is
atomic_shared_ptr,
along with its counterpart atomic_weak_ptr. As you might guess, these are the
std::shared_ptr and std::weak_ptr equivalents of std::atomic<T*>, but why
would one need them? Doesn't std::shared_ptr already have to synchronize the
reference count?
std::shared_ptr and multiple threads
std::shared_ptr works great in multiple threads, provided each thread has its
own copy or copies. In this case, the changes to the reference count are indeed
synchronized, and everything just works, provided of course that what you do
with the shared data is correctly synchronized.
class MyClass;
void thread_func(std::shared_ptr<MyClass> sp){
sp->do_stuff();
std::shared_ptr<MyClass> sp2=sp;
do_stuff_with(sp2);
}
int main(){
std::shared_ptr<MyClass> sp(new MyClass);
std::thread thread1(thread_func,sp);
std::thread thread2(thread_func,sp);
thread2.join();
thread1.join();
}In this example, you need to ensure that it is safe to call
MyClass::do_stuff() and do_stuff_with() from multiple threads concurrently
on the same instance, but the reference counts are handled OK.
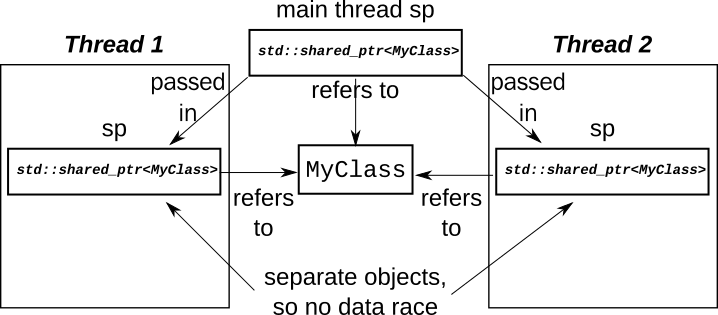
The problems come when you try and share a single std::shared_ptr instance
between threads.
Sharing a std::shared_ptr instance between threads
I could provide a trivial example of a std::shared_ptr instance shared between
threads, but instead we'll look at something a little more interesting, to give
a better feel for why you might need it.
Consider for a moment a simple singly-linked list, where each node holds a pointer to the next:
class MyList{
struct Node{
MyClass data;
std::unique_ptr<Node> next;
};
std::unique_ptr<Node> head;
// constructors etc. omitted.
};If we're going to access this from 2 threads, then we have a choice:
- We could wrap the whole object with a mutex, so only one thread is accessing the list at a time, or
- We could try and allow concurrent accesses.
For the sake of this article, we're going to assume we're allowing concurrent accesses.
Let's start simply: we want to traverse the list. Writing a traversal function is easy:
class MyList{
void traverse(std::function<void(MyClass)> f){
Node* p=head.get();
while(p){
f(p->data);
p=p->next;
}
};Assuming the list is immutable, this is fine, but immutable lists are no fun! We want to remove items from the front of our list. What changes do we need to make to support that?
Removing from the front of the list
If everything was single threaded, removing an element would be easy:
class MyList{
void pop_front(){
Node* p=head.get();
if(p){
head=std::move(p->next);
}
}
};If the list is not empty, the new head is the next pointer of the old head. However, we've got multiple threads accessing this list, so things aren't so straightforward.
Suppose we have a list of 3 elements.
A -> B -> C
If one thread is traversing the list, and another is removing the first element, there is a potential for a race.
- Thread X reads the
headpointer for the list and gets a pointer to A. - Thread Y removes A from the list and deletes it.
- Thread X tries to access the
datafor node A, but node A has been deleted, so we have a dangling pointer and undefined behaviour.
How can we fix it?
The first thing to change is to make all our std::unique_ptrs into
std::shared_ptrs, and have our traversal function take a std::shared_ptr
copy rather than using a raw pointer. That way, node A won't be deleted
immediately, since our traversing thread still holds a reference.
class MyList{
struct Node{
MyClass data;
std::shared_ptr<Node> next;
};
std::shared_ptr<Node> head;
void traverse(std::function<void(MyClass)> f){
std::shared_ptr<Node> p=head;
while(p){
f(p->data);
p=p->next;
}
}
void pop_front(){
std::shared_ptr<Node> p=head;
if(p){
head=std::move(p->next);
}
}
// constructors etc. omitted.
};Unfortunately that only fixes that race condition. There is a second race that is just as bad.
The second race condition
The second race condition is on head itself. In order to traverse the list,
thread X has to read head. In the mean time, thread Y is updating head. This
is the very definition of a data race, and is thus undefined behaviour.
We therefore need to do something to fix it.
We could use a mutex to protect head. This would be more fine-grained than a
whole-list mutex, since it would only be held for the brief time when the
pointer was being read or changed. However, we don't need to: we can use
std::experimental::atomic_shared_ptr instead.
The implementation is allowed to use a mutex internally with
atomic_shared_ptr, in which case we haven't gained anything with respect to
performance or concurrency, but we have gained by reducing the maintenance
load on our code. We don't have to have an explicit mutex data member, and we
don't have to remember to lock it and unlock it correctly around every access to
head. Instead, we can defer all that to the implementation with a single line
change:
class MyList{
std::experimental::atomic_shared_ptr<Node> head;
};Now, the read from head no longer races with a store to head: the
implementation of atomic_shared_ptr takes care of ensuring that the load gets
either the new value or the old one without problem, and ensuring that the
reference count is correctly updated.
Unfortunately, the code is still not bug free: what if 2 threads try and remove a node at the same time.
Race 3: double removal
As it stands, pop_front assumes it is the only modifying thread, which leaves
the door wide open for race conditions. If 2 threads call pop_front
concurrently, we can get the following scenario:
- Thread X loads
headand gets a pointer to node A. - Thread Y loads
headand gets a pointer to node A. - Thread X replaces
headwithA->next, which is node B. - Thread Y replaces
headwithA->next, which is node B.
So, two threads call pop_front, but only one node is removed. That's a bug.
The fix here is to use the ubiquitous compare_exchange_strong function, a staple
of any programmer who's ever written code that uses atomic variables.
class MyList{
void pop_front(){
std::shared_ptr<Node> p=head;
while(p &&
!head.compare_exchange_strong(p,p->next));
}
};If head has changed since we loaded it, then the call to
compare_exchange_strong will return false, and reload p for us. We then
loop again, checking that p is still non-null.
This will ensure that two calls to pop_front removes two nodes (if there are 2
nodes) without problems either with each other, or with a traversing thread.
Experienced lock-free programmers might well be thinking "what about the ABA problem?" right about now. Thankfully, we don't have to worry!
What no ABA problem?
That's right, pop_front does not suffer from the ABA problem. Even assuming
we've got a function that adds new values, we can never get a new value of
head the same as the old one. This is an additional benefit of using
std::shared_ptr: the old node is kept alive as long as one thread holds a
pointer. So, thread X reads head and gets a pointer to node A. This node is
now kept alive until thread X destroys or reassigns that pointer. That means
that no new node can be allocated with the same address, so if head is equal
to the value p then it really must be the same node, and not just some
imposter that happens to share the same address.
Lock-freedom
I mentioned earlier that implementations may use a mutex to provide the
synchronization in atomic_shared_ptr. They may also manage to make it
lock-free. This can be tested using the is_lock_free() member function common
to all the C++ atomic types.
The advantage of providing a lock-free atomic_shared_ptr should be obvious: by
avoiding the use of a mutex, there is greater scope for concurrency of the
atomic_shared_ptr operations. In particular, multiple concurrent reads can
proceed unhindered.
The downside will also be apparent to anyone with any experience with lock-free code: the code is more complex, and has more work to do, so may be slower in the uncontended cases. The other big downside of lock-free code (maintenance and correctness) is passed over to the implementor!
It is my belief that the scalability benefits outweight the complexity, which is
why Just::Thread v2.2 will ship with a lock-free
atomic_shared_ptr implementation.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
10th Anniversary Sale - last few days
Wednesday, 29 July 2015
The last few days of our 10th Anniversary Sale are upon us. Just::Thread and Just::Thread Pro are available for 50% off the normal price until 31st July 2015.
Just::Thread is our implementation of the C++11 and C++14 thread libraries, for Windows, Linux and MacOSX. It also includes some of the extensions from the upcoming C++ Concurrency TS, with more to come shortly.
Just::Thread Pro is our add-on library which provides an Actor framework for easier concurrency, along with concurrent data structures: a thread-safe queue, and concurrent hash map, and a wrapper for ensuring synchronized access to single objects.
All licences include a free upgrade to point releases, so if you purchase now you'll get a free upgrade to all 2.x releases.
Coming soon in v2.2
The V2.2 release of Just::Thread will be out soon. This will include the new facilities from the Concurrency TS:
Some features from the concurrency TS are already in V2.1:
All customers with V2.x licenses, including those purchased during the sale, will get a free upgrade to V2.2 when it is released.
Posted by Anthony Williams
[/ news /] permanent link
Tags: sale
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy