Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive
Wrapping Callbacks with Futures
Friday, 03 February 2017
Libraries the perform time-consuming operations, or network-based operations, often provide a means of running the task asynchronously, so that your code can continue with other things while this operation is performed in the background.
Such functions often allow you to provide a callback which is invoked when the operation has completed. The result of the operation may be supplied directly to the callback, or the callback might be expected to make further calls into the library to detect the result.
Either way, though it is a useful facility, it doesn't work well with code that needs to wait for the result — for this, you need something that can be waited on. Futures are an ideal such mechanism, because they provide a common mechanism for waiting that is abstracted away from the details of this specific library. They also allow the result to be transferred directly to the waiting thread, again abstracting away the details.
So, what do you do if the library you want to use provides a callback facility, and not a future-based wait facility? You wrap the callback in a future.
Promises, promises
The key to wrapping a callback in a future is the promise. A promise is the producer side of a future: you set the value through the promise in order to consume it via the future.
In C++, promises are provided through the std::promise class template; the
template parameter specifies the type of the data being transferred, and thus is
the same as the template parameter of the std::future that you will eventually
be returning to the user. When you call prom.set_value() on some promise
prom, then the corresponding future (retrieved by calling prom.get_future())
will become ready, holding the relevant value.
Promises and futures are not unique to C++; they are available in at least JavaScript, Python, Java and Scala, and pretty much any modern concurrency library for any language will have something that is equivalent. Adapting the examples to your favourite language is left as an exercise for the reader.
Simple callbacks
The most convenient case for us when trying to wrap a function that takes a
callback is where the function we are calling takes anything that is callable as
the callback. In C++ this might be represented as an instantiation of
std::function. e.g.
class request_data;
class retrieved_data;
void async_retrieve_data(
request_data param,
std::function<void(retrieved_data)> callback);What we need to do to wrap this is the following:
- Create a promise.
- Get the future from the promise.
- Construct a callable object that can hold the promise, and will set the value on the promise when called.
- Pass that object as the callback.
- Return the future that we obtained in step 2.
This is the same basic set of steps as we'll be doing in all the examples that follow; it is the details that will differ.
Note: std::function requires that the callable object it wraps is copyable (so
that if the std::function object itself is copied, it can copy the wrapped
callable object), so we cannot hold the std::promise itself by value, as
promises are not copyable.
We can thus write this using a C++ lambda as the callable object:
std::future<retrieved_data> wrapped_retrieve_data(request_data param) {
std::shared_ptr<std::promise<retrieved_data>> prom=
std::make_shared<std::promise<retrieved_data>>();
std::future<retrieved_data> res=prom->get_future();
async_retrieve_data(
param,
[prom](retrieved_data result){
prom->set_value(result);
});
return res;
}Here, we're using a std::shared_ptr to provide a copyable wrapper for the
promise, so that it can be copied into the lambda, and the lambda itself will be
copyable. When the copy of the lambda is called, it sets the value on the
promise through its copy of the std::shared_ptr, and the future that is
returned from wrapped_retrieve_data will become ready.
That's all very well if the function uses something like std::function for the
callback. However, in practice that's not often the case. More often you have
something that takes a plain function and a parameter to pass to this function;
an approach inherited from C. Indeed, many APIs that you might wish to wrap are
C APIs.
Plain function callbacks with a user_data parameter
A function that takes a plain function for the callback and a user_data
parameter to pass to the function often looks something like this:
void async_retrieve_data(
request_param param,
void (*callback)(uintptr_t user_data,retrieved_data data),
uintptr_t user_data);The user_data you supply to async_retrieve_data is passed as the first
parameter of your callback when the data is ready.
In this case, wrapping out callback is a bit more tricky, as we cannot just pass
our lambda directly. Instead, we must create an object, and pass something to
identify that object via the user_data parameter. Since our user_data is
uintptr_t, it is large enough to hold a pointer, so we can cast the pointer to
our object to uintptr_t, and pass it as the user_data. Our callback can then
cast it back before using it. This is a common approach when passing C++ objects
through C APIs.
The issue is: what object should we pass a pointer to, and how will its lifetime be managed?
One option is to just allocate our std::promise on the heap, and pass the
pointer to that:
void wrapped_retrieve_data_callback(uintptr_t user_data,retrieved_data data) {
std::unique_ptr<std::promise<retrieved_data>> prom(
reinterpret_cast<std::promise<retrieved_data>*>(user_data));
prom->set_value(data);
}
std::future<retrieved_data> wrapped_retrieve_data(request_data param) {
std::unique_ptr<std::promise<retrieved_data>> prom=
std::make_unique<std::promise<retrieved_data>>();
std::future<retrieved_data> res=prom->get_future();
async_retrieve_data(
param,
wrapped_retrieve_data_callback,
reinterpret_cast<uintptr_t>(prom->get()));
prom.release();
return res;
}Here, we use std::make_unique to construct our promise, and give us a
std::unique_ptr pointing to it. We then get the future as before, and call the
function we're wrapping, passing in the raw pointer, cast to an integer. We then
call release on our pointer, so the object isn't deleted when we return from
the function.
In our callback, we then cast the user_data parameter back to a pointer, and
construct a new std::unique_ptr object to take ownership of it, and ensure it
gets deleted. We can then set the value on our promise as before.
This is a little bit more convoluted than the lamda version from before, but it
works in more cases. Often the APIs will take a void* rather than a
uintptr_t, in which case you only need a static_cast rather than the scary
reinterpret_cast, but the structure is the same.
An alternative to heap-allocating the promise directly is to store it in a
global container (e.g. a std::list<std::promise<T>>), provided that its address
can't change. You then need to ensure that it gets destroyed at a suitable
point, otherwise you'll end up with a container full of used promises.
If you've only got C++11 futures, then the advantages to wrapping the callback-based API like so is primarily about abstracting away the interface, and providing a means of waiting for the result. However, if your library provides the extended futures from the C++ Concurrency TS then you can benefit from continuations to add additional functions to call when the data is ready, without having to modify the callback.
Summary
Wrapping asynchronous functions that take callbacks with futures provides a nice abstraction boundary to separate the details of the API call from the rest of your code. It is a common pattern in all languages that provide the future/promise abstraction, especially where that abstraction allows for continuations.
If you have any thoughts on this, let me know in the comments below.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: callbacks, async, futures, threading, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
TDD isn't a panacea
Wednesday, 25 January 2017
On Monday, I attended the Software Cornwall Business Connect Event. This was a day of talks and workshops for people in the local software development community here in Cornwall. One of the talks was on TDD, and how that fitted into the software development process at one of the larger software companies in the area.
There was an interesting question asked by one of the attendees: how do you know that your tests are correct? What if you make a mistake in your tests, and then change the code to make it pass?
The answer that the presenter gave, and the one that is most common in the literature, is that the tests check the code, and the code checks the tests. There was a brief discussion around this point, but I thought that it was worth elaborating here.
Baby steps
One of the key parts of TDD is the idea of "baby steps". You write code incrementally, with small changes, and small, focused tests.
Consequently, when you write a new test, you're testing some small change you're about to make. If you make a mistake, this gives you a reasonable chance of spotting it.
However, that's still relying on you spotting it yourself. You just wrote the test, and it's very easy to read back what you intended to write, rather than what you actually did write. This is where "the code checks the tests" comes in.
Red
The TDD cycle is often dubbed "Red, Green, Refactor". At this point, the relevant part is "Red" — you just wrote a new test, so it should fail. If you run it, and it passes then something is wrong, most likely a mistake in the test. This gives you a second chance to revisit the test, and ensure that it is indeed correct. Maybe you mistyped one of the values; maybe you missed a function call. Either way, this gives you a second chance to verify the test.
OK, so you wrote the test (wrong), the test fails (as expected), so you write the code to make it pass. This gives you the next opportunity to verify the test.
Green
TDD doesn't exempt you from thinking. You don't just write a test and then blindly make it pass. You write a test, often with an idea of the code change you're going to make to make it pass.
So, you've written a failing test, and you make the desired change. You run the tests, and the new test still fails. You haven't got the "Green" outcome you desired or intended. Obviously, the first thing to check here is the code, but it also gives you another chance to check the test. If the code really does do what you intended, then the test must be wrong, and vice versa.
Of course, we don't have just the one test, unless this is the beginning of a project. We have other tests on the code. If the new test is incorrect, and thus inconsistent with the previous tests, then changing the code to make the new test pass may well cause previous tests to fail.
At this point, you've got to be certain that the test is right if you're going to change the code. Alternatively, you made exactly the same mistake in the code as you did in the test, and the test passes anyway. Either way, this is the point at which the faulty test becomes faulty code.
It's not the last chance we have to check the test, though: the final step in the TDD loop is "Refactor".
Refactor
Refactoring is about simplifying your code — removing duplication, applying general algorithms rather than special cases, and so forth. If you've made a mistake in a test, then the implementation may well end up with a special case to handle that particular eventuality; the code will be resistant to simplification because that test is inconsistent with the others. Again, TDD does not exempt you from thinking. If you intended to implement a particular algorithm, and the code does not simplify in a way that is consistent with that algorithm then this is a red flag — something is not right, and needs checking. This gives you yet another chance to inspect the test, and verify that it is indeed correct.
At this point, if you still haven't fixed your test, then you have now baked the mistake into your code. However, all is not lost: "Red, Green, Refactor" is a cycle, so we begin again, with the next test.
More tests
As we add more tests, we get more and more opportunities to verify the correctness of the existing tests. As we adjust the code to make future tests pass, we can spot inconsistencies, and we can observe that changes we make break the earlier test. When we see the broken test, this gives us a further opportunity to verify that the test is indeed correct, and potentially fix it, rather than fixing the code.
Acceptance tests then provide a further level of checking, though these tend to be far courser-grained, so may work fine unless the particular inputs happen to map to those in the incorrect lower level test.
TDD is not a panacea; but it is a useful tool
So, it is possible that a mistake in a test will be matched by incorrect code, and this will make it into production. However, in my experience, this is unlikely if the incorrect test is merely a mistake. Instead, the bugs that make it through tend to fall into two categories:
- errors of omission — I didn't think to check that scenario, or
- errors due to misunderstanding — my understanding of the requirements didn't match what was wanted, and the code does exactly what I intended, but not what the client intended.
TDD is not a panacea, and won't fix all your problems, but it is a useful tool, and has the potential to greatly reduce the number of bugs in your code.
Please let me know what you think by adding a comment.
Posted by Anthony Williams
[/ testing /] permanent link
Tags: tdd, testing, bugs
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Christmas Sale
Tuesday, 06 December 2016
It's coming up to Christmas, and we're getting in the festive mood, so we're running a sale: Just::Thread Pro will be available for 50% off the normal price until the end of December 2016.
Just::Thread Pro provides high level facilities
on top of the C++ Standard Thread Library: an
Actor framework for easier
concurrency, along with concurrent data structures: a
thread-safe queue,
and
concurrent hash map,
and a wrapper for ensuring
synchronized access to single objects,
as well as an implementation of the Concurrency TS, including
atomic_shared_ptr
and
continuations
All licences include a free upgrade to point releases, so if you purchase now you'll get a free upgrade to all 2.x releases.
Posted by Anthony Williams
[/ news /] permanent link
Tags: sale
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Reclaiming Data Structures with Cycles
Friday, 14 October 2016
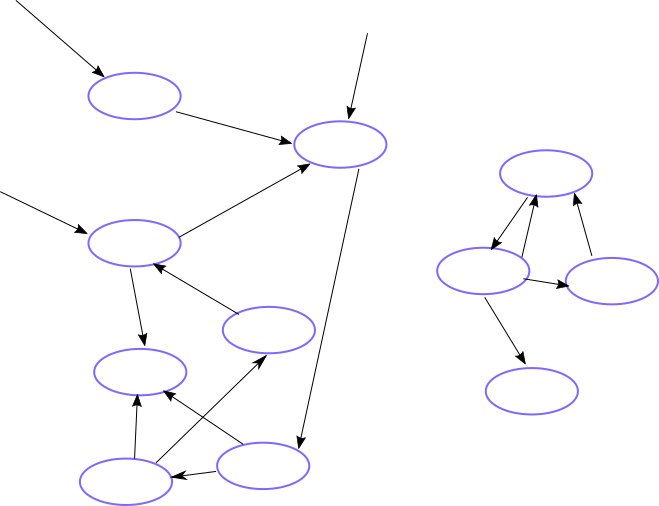
In my CppCon 2016 Trip Report I mentioned Herb Sutter's Plenary, and his deferred reclamation library. The problem to be solved is that some data structures cannot be represented as a DAG, where each node in the structure has a clear owner; these data structures are general graphs, where any node may hold a pointer to any other node, and thus you cannot say that a node is no longer needed just because one of the pointers to it has been removed. Likewise, it is possible that there may be a whole segment of the data structure which is no longer accessible from outside, and the only remaining pointers are those internal to the data structure. This whole section should therefore be destroyed, otherwise we have a leak.
In the data structure shown below, the left-hand set of nodes have 3 external pointers keeping them alive, but the right-hand set are not accessible from outside, and so should be destroyed.
Deferred Reclamation
Herb's solution is to use a special pointer type deferred_ptr<T>, and a
special heap and allocator to create the nodes. You can then explicitly check
for inaccessible nodes by calling collect() on the heap object, or rely on all
the nodes being destroyed when the heap itself is destroyed. For the details,
see Herb's description.
One thing that stood out for me was the idea that destruction was deferred — nodes are not reclaimed immediately, but at some later time. Also, the use of a custom allocator seemed unusual. I wondered if there was an alternative way of handling things.
Internal pointers vs Root pointers
I've been contemplating the issue for the last couple of weeks, and come up with an alternative scheme that destroys unreachable objects as soon as they become unreachable, even if those unreachable objects hold pointers to each other. Rather than using a custom heap and allocator, it uses a custom base class, and distinct pointer types for internal pointers and root pointers.
My library is also still experimental, but the source code is freely available under the BSD license.
The library provides two smart pointer class templates: root_ptr<T> and
internal_ptr<T>. root_ptr<T> is directly equivalent to
std::shared_ptr<T>: it is a reference-counted smart pointer. For many uses,
you could use root_ptr<T> as a direct replacement for std::shared_ptr<T>
and your code will have identical behaviour. root_ptr<T> is intended to
represent an external owner for your data structure. For a tree it could
hold the pointer to the root node. For a general graph it could be used to hold
each of the external nodes of the graph.
The difference comes with internal_ptr<T>. This holds a pointer to another
object within the data structure. It is an internal pointer to another
part of the same larger data structure. It is also reference counted, so if
there are no root_ptr<T> or internal_ptr<T> objects pointing to a given
object then it is immediately destroyed, but even one internal_ptr<T> can be
enough to keep an object alive as part of a larger data structure.
The "magic" is that if an object is only pointed to by internal_ptr<T>
pointers, then it is only kept alive as long as the whole data structure has an
accessible root in the form of an root_ptr<T> or an object with an
internal_ptr<T> that is not pointed to by either an root_ptr<T> or an
internal_ptr<T>.
This is made possible by the internal nodes deriving from internal_base, much
like std::enable_shared_from_this<T> enables additional functionality when
using std::shared_ptr<T>. This base class is then passed to the
internal_ptr<T> constructor, to identify which object the internal_ptr<T>
belongs to.
For example, a singly-linked list could be implemented like so:
class List{
struct Node: jss::internal_base{
jss::internal_ptr<Node> next;
data_type data;
Node(data_type data_):next(this),data(data_){}
};
jss::root_ptr<Node> head;
public:
void push_front(data_type new_data){
auto new_node=jss::make_owner<Node>(new_data);
new_node->next=head;
head=new_node;
}
data_type pop_front(){
auto old_head=head;
if(!old_head)
throw std::runtime_error("Empty list");
head=old_head->next;
return old_head->data;
}
void clear(){
head.reset();
}
};This actually has an advantage over using std::shared_ptr<Node> for the links
in the list, due to another feature of the library. When a group of interlinked
nodes becomes unreachable, then firstly each node is marked as unreachable, thus
making any internal_ptr<T>s that point to them become equal to nullptr. Then
all the unreachable nodes are destroyed in turn. All this is done with iteration
rather than recursion, and thus avoids the deep recursive destructor chaining
that can occur when using std::shared_ptr<T>. This is similar to the behaviour
of Herb's deferred_ptr<T> during a collect() call on the deferred_heap.
local_ptr<T> completes the set: you can use a local_ptr<T> when traversing a
data structure that uses internal_ptr<T>. local_ptr<T> does not hold a
reference, and is not in any way involved in the lifetime tracking of the
nodes. It is intended to be used when you need to keep a local pointer to a
node, but you're not updating the data structure, and don't need that pointer to
keep the node alive. e.g.
class List{
// as above
public:
void for_each(std::function<void(data_type&)> f){
jss::local_ptr<Node> node=head;
while(node){
f(node->data);
node=node->next;
}
}
}Warning: root_ptr<T> and internal_ptr<T> are not safe for use if
multiple threads may be accessing any of the nodes in the data structure while
any thread is modifying any part of it. The data structure as a whole
must be protected with external synchronization in a multi-threaded context.
How it works
The key to this system is twofold. Firstly the nodes in the data structure
derive from internal_base, which allows the library to store a back-pointer to
the smart pointer control block in the node itself, as long as the head of the
list of internal_ptr<T>s that belong to that node. Secondly, the control
blocks each hold a list of back-pointers to the control blocks of the objects
that point to them via internal_ptr<T>. When a reference to a node is dropped
(either from an root_ptr<T> or an internal_ptr<T>), if that node has no
remaining root_ptr<T>s that point to it, the back-pointers are checked. The
chain of back-pointers is followed until either a node is found that has an
root_ptr<T> that points to it, or a node is found that does not have a
control block (e.g. because it is allocated on the stack, or owned by
std::shared_ptr<T>). If either is found, then the data structure is
reachable, and thus kept alive. If neither is found once all the
back-pointers have been followed, then the set of nodes that were checked is
unreachable, and thus can be destroyed. Each of the unreachable nodes is then
marked as such, which causes internal_ptr<T>s that refer to them to become
nullptr, and thus prevents resurrection of the nodes. Finally, the unreachable
nodes are all destroyed in an unspecified order. The scan and destroy is done
with iteration rather than recursion to avoid the potential for deep recursive
nesting on large interconnected graphs of nodes.
The downside is that the time taken to drop a reference to a node is dependent on the number of nodes in the data structure, in particular the number of nodes that have to be examined in order to find an owned node.
Note: only dropping a reference to a node (destroying a pointer, or reassigning a pointer) incurs this cost. Constructing the data structure is still relatively low overhead.
Feedback
Please let me know if you have any comments on my internal pointer library, especially if you have either used it successfully, or have tried to use it and found it doesn't work for you.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, reference counting, garbage collection
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
CppCon 2016 Trip Report
Wednesday, 12 October 2016
So, CppCon 2016 has finished, and I'm back home and all caught up with "normal" life again. I thought it was about time I wrote up my trip report before it was too late.
Pre-conference Workshop
For me, the conference started on Saturday 17th September, as I was running a two-day workshop on Concurrent Thinking. This was well-attended, and I had some great conversations with people during the breaks and at the end of each day.
The main conference
The main conference started on Monday morning, with a keynote from Bjarne Stroustrup on the evolution of C++. He walked us through how far C++ has come since its humble beginnings, and what he hopes to see in the future — essentially all those things he hoped to see in C++17 that didn't make it, plus a couple of extras.
Over the course of the rest of the week there were over 100 sessions across a wide variety of C++-related topics. It was often hard to choose which session to go and see, but since everything was recorded, it was possible to catch up afterwards by watching the CppCon Youtube Channel.
Highlights for me included:
-
Kenny Kerr and James McNellis on Embracing Standard C++ for the Windows Runtime (Video). Kenny and James talked about the new standard C++ projection for the Windows Runtime, which provides essentially a set of smart pointer wrappers for all the Windows Runtime types to hide the messy COM-style boilerplate that would otherwise be required. They compared a simple .NET app, the pages of boilerplate code required today in C++ to do the same, and then showed how it is again simple with the new library. I look forward to being able to use it for writing Windows-based applications.
-
Hartmut Kaiser on Parallelism in Modern C++ (Video). Hartmut talked about the new parallel STL, how futures and asynchronous operations work together to take advantage of parallel hardware, and issues like data placement, vectorization, and the potential for moving work to GPUs.
- Michael Spencer on My Little Optimizer: Undefined Behavior is Magic (Video). Michael showed how the presence of undefined behaviour can drasticly change the output of code generated by an optimizing compiler, and can actually let it generate better code. This was very interesting to see. We all know that we need to avoid undefined behaviour, but it's enlightening to see how the existence of undefined behaviour at all can improve optimization.
Every presentation I watched was great, but these stood out. I still have a long list of sessions I'm going to watch on video; there is just so much to take in.
The plenary was by Herb Sutter, who talked about "Leak Freedom by default". The first half of the
talk was a summary of what we have in the standard library today — std::unique_ptr<T> and
std::shared_ptr<T> do most of the heavy lifting. He showed a poster "to stick on your colleague's
wall" showing which to use when. The remainder of the talk was discussion around the remaining
cases, notably those data structures with cycles, which are not well-supported by today's
standard library. In particular, Herb introduced his "experimental" deferred-reclamation (i.e. Garbage
Collection) library, which uses a custom heap and
deferred_ptr<T> to allow you to detect and destroy unreachable objects. This got me thinking if
there was another way to do it, which will be the subject of a later blog post.
The people
By far the best part of the conference is the people. I had many in-depth discussions with people that would be hard to have via email. It was great to meet people face to face; some I was meeting for the first time, and others who I haven't met in person for years.
While you can watch the videos and read the slides without attending, there is no substitute for the in-person interactions.
My sessions
As well as the workshop, I presented a talk on The Continuing Future of C++ Concurrency, which was on Tuesday afternoon, and then I was on the panel for the final session of the conference: Implementing the C++ Standard Library on Friday afternoon.
As for the other sessions, videos are available on the CppCon Youtube channel:
Plus, you can also download my slides for The Continuing Future of C++ Concurrency.
Posted by Anthony Williams
[/ news /] permanent link
Tags: conferences, cppcon, C++, concurrency, workshop, slides
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
CppCon 2016 Workshop and Talk
Monday, 08 August 2016
I will be running my new 2-day workshop on Concurrent Thinking, as well as doing a session on The Continuing Future of Concurrency in C++ at CppCon 2016 in September.
I rarely leave the UK, and haven't been to the USA for 20 years, so this should be exciting. The CppCon program looks jam-packed with interesting talks, so it'll be hard to choose which to attend, and I'm looking forward to talking face-to-face with people I've only previously conversed with via email.
My workshop is on 17th-18th September, and the main conference is running 19th-23rd. If you haven't got your ticket already, head on over to CppCon Registration to get yours now.
Hope to see you there!
Posted by Anthony Williams
[/ news /] permanent link
Tags: conferences, cppcon, C++, concurrency, workshop
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
just::thread Pro adds gcc 6 support
Thursday, 21 July 2016
I am pleased to announce that just::thread Pro
now supports gcc 5 and 6 on Ubuntu Linux.
The code has also been refactored, so with Microsoft Visual Studio 2015, g++ 5
or g++ 6 you can use the just::thread Pro enhancements on top of the
platform-supplied version of the C++14 thread library. For older compilers, and
for MacOSX, the just::thread compatibility library is still required.
Dubbed just::thread Pro Standalone, the new build features all the same
facilities as the previous release:
- A multiple-producer single-consumer FIFO queue, ideal for sending messages to a particular thread
- A
synchronized_valueclass template for synchronizing access to a single object - A thread-safe hash map
- An Actor framework for simplified design of multi-threaded applications
- A variadic
jss::lock_guardclass template to allow acquiring multiple locks at once, like the new C++17std::lock_guard. - New facilities from the
Concurrency TS:
- A lock-free implementation of
atomic_shared_ptrandatomic_weak_ptr— see Anthony's earlier blog post onatomic_shared_ptr - Latches — signal waiting threads once a specified number of count-down events have occurred.
- Barriers — block a group of threads until they are all ready to proceed.
future::then()— schedule a task to run when a future becomes ready.when_any()— create a future that is ready when any of a set of futures is ready.when_all()— create a future that is ready when all of a set of futures are ready.
- A lock-free implementation of
Get your copy of just::thread Pro
Purchase your copy and get started now.
As usual, all customers with V2.x licenses of just::thread Pro will get a free
upgrade to the new just::thread Pro Standalone edition.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++11
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
NDC Oslo 2016 Presentation Slides
Friday, 24 June 2016
NDC Oslo 2016 was 6th-10th June 2016.
I thoroughly enjoyed the conference. There were 9 tracks to choose from, so there was a wide range of topics covered. Though I mostly attended talks from the C++ track, I did branch out on a couple of occasions, espcially for the fun sessions, such as "Have I got NDC Oslo for you".
I ran my new 2-day workshop on Concurrent Thinking, which went well, with 23 students.
I also did two presentations:
- The Continuing Future of C++ Concurrency
- Safety: off --- How not to shoot yourself in the foot with C++ atomics
Slides for the presentations are available here:
- Slides for The Continuing Future of C++ Concurrency
- Slides for Safety: off --- How not to shoot yourself in the foot with C++ atomics
The videos are also being published on Vimeo:
- Video for The Continuing Future of C++ Concurrency
- Video for Safety: off --- How not to shoot yourself in the foot with C++ atomics
Posted by Anthony Williams
[/ news /] permanent link
Tags: conferences, ndc, C++, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
NDC Oslo 2016
Monday, 30 May 2016
It's a week to go before NDC Oslo 2016. The conference starts on Monday 6th June with 2 days of workshops and runs through to Friday 10th June.
I will be running my new 2-day workshop on Concurrent Thinking, as well as doing two presentations:
- The Continuing Future of C++ Concurrency
- Safety: off --- How not to shoot yourself in the foot with C++ atomics
With 163 speakers including Andrei Alexandrescu and Joe Armstrong, and 5 tracks it looks to be an exciting conference.
Hope to see you there!
Posted by Anthony Williams
[/ news /] permanent link
Tags: conferences, ndc, C++, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Slides for my ACCU 2016 presentation
Friday, 29 April 2016
Now that the ACCU 2016 conference is over, and we've all had a chance to recover, I figured it was time to post the slides from my presentation.
My session was titled "Concurrent Thinking". It was well-attended, with people standing round the edges due to the lack of seats, and I had people say afterwards that they liked it, which is always nice. I hope everyone learned something useful. Here's the abstract:
One of the most difficult issues around designing software with multiple threads of execution is synchronizing data.
Whether you use actors, active objects, futures and continuations or mutable shared state, every non-trivial system with multiple threads needs to transfer data between them. This means thinking about which data needs to be processed by which thread, and ensuring that the right data gets to the right threads in the right order. It also means thinking about API design to avoid race conditions.
In this presentation I’ll describe techniques we can use when doing this "thinking", as well as the tools we have available to help us describe our requirements and enforce them in code.
All examples will use C++, but the thought processes are widely applicable.
The slides are available here.
Posted by Anthony Williams
[/ news /] permanent link
Tags: C++, lockfree, atomic, accu
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2024 Just Software Solutions Ltd. All rights reserved. | Privacy Policy