Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Multithreading and Concurrency
My book, C++ Concurrency in Action contains a detailed description of the C++11 threading facilities, and techniques for designing concurrent code.
The just::thread implementation of the new
C++11 and C++14 thread library is available for Microsoft
Visual Studio 2005, 2008, 2010, 2012, 2013 and 2015, and TDM gcc 4.5.2, 4.6.1 and 4.8.1 on Windows, g++ 4.3, 4.4, 4.5, 4.6, 4.7, 4.8 and 4.9 on Linux, and MacPorts g++ 4.3, 4.4, 4.5, 4.6, 4.7 and 4.8 on MacOSX. Order your copy today.
Memory Models and Synchronization
Monday, 24 November 2008
I have read a couple of posts on memory models over the couple of weeks: one from Jeremy Manson on What Volatile Means in Java, and one from Bartosz Milewski entitled Who ordered sequential consistency?. Both of these cover a Sequentially Consistent memory model — in Jeremy's case because sequential consistency is required by the Java Memory Model, and in Bartosz' case because he's explaining what it means to be sequentially consistent, and why we would want that.
In a sequentially consistent memory model, there is a single total order of all atomic operations which is the same across all processors in the system. You might not know what the order is in advance, and it may change from execution to execution, but there is always a total order.
This is the default for the new C++0x atomics, and required for
Java's volatile, for good reason — it is
considerably easier to reason about the behaviour of code that uses
sequentially consistent orderings than code that uses a more relaxed
ordering.
The thing is, C++0x atomics are only sequentially consistent by default — they also support more relaxed orderings.
Relaxed Atomics and Inconsistent Orderings
I briefly touched on the properties of relaxed atomic operations in my presentation on The Future of Concurrency in C++ at ACCU 2008 (see the slides). The key point is that relaxed operations are unordered. Consider this simple example with two threads:
#include <thread>
#include <cstdatomic>
std::atomic<int> x(0),y(0);
void thread1()
{
x.store(1,std::memory_order_relaxed);
y.store(1,std::memory_order_relaxed);
}
void thread2()
{
int a=y.load(std::memory_order_relaxed);
int b=x.load(std::memory_order_relaxed);
if(a==1)
assert(b==1);
}
std::thread t1(thread1);
std::thread t2(thread2);
All the atomic operations here are using
memory_order_relaxed, so there is no enforced
ordering. Therefore, even though thread1 stores
x before y, there is no guarantee that the
writes will reach thread2 in that order: even if
a==1 (implying thread2 has seen the result
of the store to y), there is no guarantee that
b==1, and the assert may fire.
If we add more variables and more threads, then each thread may see a different order for the writes. Some of the results can be even more surprising than that, even with two threads. The C++0x working paper features the following example:
void thread1()
{
int r1=y.load(std::memory_order_relaxed);
x.store(r1,std::memory_order_relaxed);
}
void thread2()
{
int r2=x.load(std::memory_order_relaxed);
y.store(42,std::memory_order_relaxed);
assert(r2==42);
}
There's no ordering between threads, so thread1 might
see the store to y from thread2, and thus
store the value 42 in x. The fun part comes because the
load from x in thread2 can be reordered
after everything else (even the store that occurs after it in the same
thread) and thus load the value 42! Of course, there's no guarantee
about this, so the assert may or may not fire — we
just don't know.
Acquire and Release Ordering
Now you've seen quite how scary life can be with relaxed operations, it's time to look at acquire and release ordering. This provides pairwise synchronization between threads — the thread doing a load sees all the changes made before the corresponding store in another thread. Most of the time, this is actually all you need — you still get the "two cones" effect described in Jeremy's blog post.
With acquire-release ordering, independent reads of variables written independently can still give different orders in different threads, so if you do that sort of thing then you still need to think carefully. e.g.
std::atomicx(0),y(0); void thread1() { x.store(1,std::memory_order_release); } void thread2() { y.store(1,std::memory_order_release); } void thread3() { int a=x.load(std::memory_order_acquire); int b=y.load(std::memory_order_acquire); } void thread4() { int c=x.load(std::memory_order_acquire); int d=y.load(std::memory_order_acquire); }
Yes, thread3 and thread4 have the same
code, but I separated them out to make it clear we've got two separate
threads. In this example, the stores are on separate threads, so there
is no ordering between them. Consequently the reader threads may see
the writes in either order, and you might get a==1 and
b==0 or vice versa, or both 1 or both 0. The fun part is
that the two reader threads might see opposite
orders, so you have a==1 and b==0, but
c==0 and d==1! With sequentially consistent
code, both threads must see consistent orderings, so this would be
disallowed.
Summary
The details of relaxed memory models can be confusing, even for experts. If you're writing code that uses bare atomics, stick to sequential consistency until you can demonstrate that this is causing an undesirable impact on performance.
There's a lot more to the C++0x memory model and atomic operations than I can cover in a blog post — I go into much more depth in the chapter on atomics in my book.
Posted by Anthony Williams
[/ threading /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Deadlock Detection with just::thread
Wednesday, 12 November 2008
One of the biggest problems with multithreaded programming is the
possibility of deadlocks. In the excerpt from my
book published over at codeguru.com (Deadlock:
The problem and a solution) I discuss various ways of dealing with
deadlock, such as using std::lock when acquiring multiple
locks at once and acquiring locks in a fixed order.
Following such guidelines requires discipline, especially on large
code bases, and occasionally we all slip up. This is where the
deadlock detection mode of the
just::thread library comes in: if you compile your
code with deadlock detection enabled then if a deadlock occurs the
library will display a stack trace of the deadlock threads
and the locations at which the synchronization
objects involved in the deadlock were locked.
Let's look at the following simple code for an example.
#include <thread>
#include <mutex>
#include <iostream>
std::mutex io_mutex;
void thread_func()
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from thread_func"<<std::endl;
}
int main()
{
std::thread t(thread_func);
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from main thread"<<std::endl;
t.join();
return 0;
}
Now, it is obvious just from looking at the code that there's a
potential deadlock here: the main thread holds the lock on
io_mutex across the call to
t.join(). Therefore, if the main thread manages to lock
the io_mutex before the new thread does then the program
will deadlock: the main thread is waiting for thread_func
to complete, but thread_func is blocked on the
io_mutex, which is held by the main thread!
Compile the code and run it a few times: eventually you should hit the deadlock. In this case, the program will output "Hello from main thread" and then hang. The only way out is to kill the program.
Now compile the program again, but this time with
_JUST_THREAD_DEADLOCK_CHECK defined — you can
either define this in your project settings, or define it in the first
line of the program with #define. It must be defined
before any of the thread library headers are included
in order to take effect. This time the program doesn't hang —
instead it displays a message box with the title "Deadlock Detected!"
looking similar to the following:
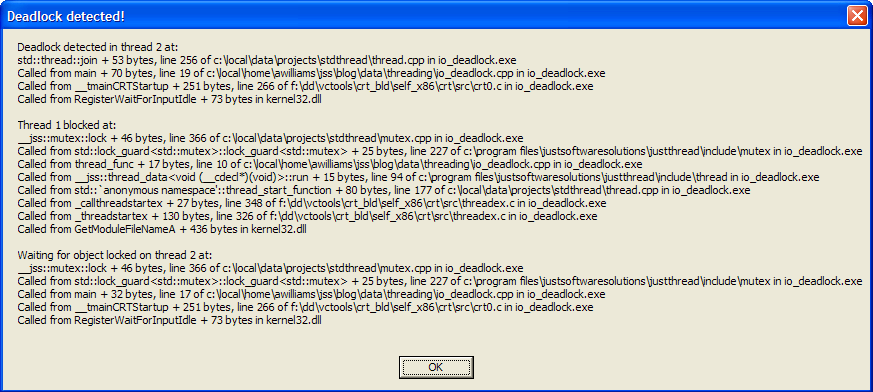
Of course, you need to have debug symbols for your executable to get meaningful stack traces.
Anyway, this message box shows three stack traces. The first is
labelled "Deadlock detected in thread 2 at:", and tells us that the
deadlock was found in the call to std::thread::join from
main, on line 19 of our source file
(io_deadlock.cpp). Now, it's important to note that "line 19" is
actually where execution will resume when join returns
rather than the call site, so in this case the call to
join is on line 18. If the next statement was also on
line 18, the stack would report line 18 here.
The next stack trace is labelled "Thread 1 blocked at:", and tells
us where the thread we're trying to join with is blocked. In this
case, it's blocked in the call to mutex::lock from the
std::lock_guard constructor called from
thread_func returning to line 10 of our source file (the
constructor is on line 9).
The final stack trace completes the circle by telling us where that
mutex was locked. In this case the label says "Waiting for object
locked on thread 2 at:", and the stack trace tells us it was the
std::lock_guard constructor in main
returning to line 17 of our source file.
This is all the information we need to see the deadlock in this case, but in more complex cases we might need to go further up the call stack, particularly if the deadlock occurs in a function called from lots of different threads, or the mutex being used in the function depends on its parameters.
The just::thread deadlock
detection can help there too: if you're running the application from
within the IDE, or you've got a Just-in-Time debugger installed then
the application will now break into the debugger. You can then use the
full capabilities of your debugger to examine the state of the
application when the deadlock occurred.
Try It Out
You can download sample Visual C++ Express 2008 project for this
example, which you can use with our just::thread
implementation of the new C++0x thread library. The code should also
work with g++.
just::thread
doesn't just work with Microsoft Visual Studio 2008 — it's also
available for g++ 4.3 on Ubuntu Linux. Get your copy
today and try out the deadlock detection feature
risk free with our 30-day money-back guarantee.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: multithreading, deadlock, c++
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Implementing a Thread-Safe Queue using Condition Variables (Updated)
Tuesday, 16 September 2008
One problem that comes up time and again with multi-threaded code is how to transfer data from one thread to another. For example, one common way to parallelize a serial algorithm is to split it into independent chunks and make a pipeline — each stage in the pipeline can be run on a separate thread, and each stage adds the data to the input queue for the next stage when it's done. For this to work properly, the input queue needs to be written so that data can safely be added by one thread and removed by another thread without corrupting the data structure.
Basic Thread Safety with a Mutex
The simplest way of doing this is just to put wrap a non-thread-safe queue, and protect it with a mutex (the examples use the types and functions from the upcoming 1.35 release of Boost):
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
public:
void push(const Data& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
Data& front()
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
Data const& front() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
void pop()
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.pop();
}
};
This design is subject to race conditions between calls to empty, front and pop if there
is more than one thread removing items from the queue, but in a single-consumer system (as being discussed here), this is not a
problem. There is, however, a downside to such a simple implementation: if your pipeline stages are running on separate threads,
they likely have nothing to do if the queue is empty, so they end up with a wait loop:
while(some_queue.empty())
{
boost::this_thread::sleep(boost::posix_time::milliseconds(50));
}
Though the sleep avoids the high CPU consumption of a direct busy wait, there are still some obvious downsides to
this formulation. Firstly, the thread has to wake every 50ms or so (or whatever the sleep period is) in order to lock the mutex,
check the queue, and unlock the mutex, forcing a context switch. Secondly, the sleep period imposes a limit on how fast the thread
can respond to data being added to the queue — if the data is added just before the call to sleep, the thread
will wait at least 50ms before checking for data. On average, the thread will only respond to data after about half the sleep time
(25ms here).
Waiting with a Condition Variable
As an alternative to continuously polling the state of the queue, the sleep in the wait loop can be replaced with a condition
variable wait. If the condition variable is notified in push when data is added to an empty queue, then the waiting
thread will wake. This requires access to the mutex used to protect the queue, so needs to be implemented as a member function of
concurrent_queue:
template<typename Data>
class concurrent_queue
{
private:
boost::condition_variable the_condition_variable;
public:
void wait_for_data()
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
}
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
There are three important things to note here. Firstly, the lock variable is passed as a parameter to
wait — this allows the condition variable implementation to atomically unlock the mutex and add the thread to the
wait queue, so that another thread can update the protected data whilst the first thread waits.
Secondly, the condition variable wait is still inside a while loop — condition variables can be subject to
spurious wake-ups, so it is important to check the actual condition being waited for when the call to wait
returns.
Be careful when you notify
Thirdly, the call to notify_one comes after the data is pushed on the internal queue. This avoids the
waiting thread being notified if the call to the_queue.push throws an exception. As written, the call to
notify_one is still within the protected region, which is potentially sub-optimal: the waiting thread might wake up
immediately it is notified, and before the mutex is unlocked, in which case it will have to block when the mutex is reacquired on
the exit from wait. By rewriting the function so that the notification comes after the mutex is unlocked, the
waiting thread will be able to acquire the mutex without blocking:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
lock.unlock(); // unlock the mutex
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
Reducing the locking overhead
Though the use of a condition variable has improved the pushing and waiting side of the interface, the interface for the consumer
thread still has to perform excessive locking: wait_for_data, front and pop all lock the
mutex, yet they will be called in quick succession by the consumer thread.
By changing the consumer interface to a single wait_and_pop function, the extra lock/unlock calls can be avoided:
template<typename Data>
class concurrent_queue
{
public:
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
// rest as before
};
Using a reference parameter to receive the result is used to transfer ownership out of the queue in order to avoid the exception
safety issues of returning data by-value: if the copy constructor of a by-value return throws, then the data has been removed from
the queue, but is lost, whereas with this approach, the potentially problematic copy is performed prior to modifying the queue (see
Herb Sutter's Guru Of The Week #8 for a discussion of the issues). This does, of
course, require that an instance Data can be created by the calling code in order to receive the result, which is not
always the case. In those cases, it might be worth using something like boost::optional to avoid this requirement.
Handling multiple consumers
As well as removing the locking overhead, the combined wait_and_pop function has another benefit — it
automatically allows for multiple consumers. Whereas the fine-grained nature of the separate functions makes them subject to race
conditions without external locking (one reason why the authors of the SGI
STL advocate against making things like std::vector thread-safe — you need external locking to do many common
operations, which makes the internal locking just a waste of resources), the combined function safely handles concurrent calls.
If multiple threads are popping entries from a full queue, then they just get serialized inside wait_and_pop, and
everything works fine. If the queue is empty, then each thread in turn will block waiting on the condition variable. When a new
entry is added to the queue, one of the threads will wake and take the value, whilst the others keep blocking. If more than one
thread wakes (e.g. with a spurious wake-up), or a new thread calls wait_and_pop concurrently, the while
loop ensures that only one thread will do the pop, and
the others will wait.
Update: As commenter David notes below, using multiple consumers does have one problem: if there are several
threads waiting when data is added, only one is woken. Though this is exactly what you want if only one item is pushed onto the
queue, if multiple items are pushed then it would be desirable if more than one thread could wake. There are two solutions to this:
use notify_all() instead of notify_one() when waking threads, or to call notify_one()
whenever any data is added to the queue, even if the queue is not currently empty. If all threads are notified then the extra
threads will see it as a spurious wake and resume waiting if there isn't enough data for them. If we notify with every
push() then only the right number of threads are woken. This is my preferred option: condition variable notify calls
are pretty light-weight when there are no threads waiting. The revised code looks like this:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
// rest as before
};
There is one benefit that the separate functions give over the combined one — the ability to check for an empty queue, and
do something else if the queue is empty. empty itself still works in the presence of multiple consumers, but the value
that it returns is transitory — there is no guarantee that it will still apply by the time a thread calls
wait_and_pop, whether it was true or false. For this reason it is worth adding an additional
function: try_pop, which returns true if there was a value to retrieve (in which case it retrieves it), or
false to indicate that the queue was empty.
template<typename Data>
class concurrent_queue
{
public:
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
// rest as before
};
By removing the separate front and pop functions, our simple naive implementation has now become a
usable multiple producer, multiple consumer concurrent queue.
The Final Code
Here is the final code for a simple thread-safe multiple producer, multiple consumer queue:
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
boost::condition_variable the_condition_variable;
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
};
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, thread safe, queue, condition variable
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The Intel x86 Memory Ordering Guarantees and the C++ Memory Model
Tuesday, 26 August 2008
The July 2008 version of the Intel 64 and IA-32 Architecture documents includes the information from the memory ordering white paper I mentioned before. This makes it clear that on x86/x64 systems the preferred implementation of the C++0x atomic operations is as follows (which has been confirmed in discussions with Intel engineers):
| Memory Ordering | Store | Load |
|---|---|---|
| std::memory_order_relaxed | MOV [mem],reg | MOV reg,[mem] |
| std::memory_order_acquire | n/a | MOV reg,[mem] |
| std::memory_order_release | MOV [mem],reg | n/a |
| std::memory_order_seq_cst | XCHG [mem],reg | MOV reg,[mem] |
As you can see, plain MOV is enough for even
sequentially-consistent loads if a LOCKed instruction
such as XCHG is used for the sequentially-consistent
stores.
One thing to watch out for is the Non-Temporal SSE instructions
(MOVNTI, MOVNTQ, etc.), which by their
very nature (i.e. non-temporal) don't follow the normal
cache-coherency rules. Therefore non-temporal stores must be
followed by an SFENCE instruction in order for their
results to be seen by other processors in a timely fashion.
Additionally, if you're writing drivers which deal with memory pages marked WC (Write-Combining) then additional fence instructions will be required to ensure visibility between processors. However, if you're programming with WC pages then this shouldn't be a problem.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: intel, x86, c++, threading, memory ordering, memory model
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Condition Variable Spurious Wakes
Friday, 27 June 2008
Condition variables are a useful mechanism for waiting until an
event occurs or some "condition" is satisfied. For example, in my implementation
of a thread-safe queue I use a condition variable to avoid
busy-waiting in wait_and_pop() when the queue is
empty. However, condition variables have one "feature" which is a
common source of bugs: a wait on a condition variable may return even
if the condition variable has not been notified. This is called a
spurious wake.
Spurious wakes cannot be predicted: they are essentially random from the user's point of view. However, they commonly occur when the thread library cannot reliably ensure that a waiting thread will not miss a notification. Since a missed notification would render the condition variable useless, the thread library wakes the thread from its wait rather than take the risk.
Bugs due to spurious wakes
Consider the code for wait_and_pop from my thread-safe
queue:
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
If we know that there's only one consumer thread, it would be
tempting to write this with an if instead of a
while, on the assumption that there's only one thread
waiting, so if it's been notified, the queue must not be empty:
if(the_queue.empty()) // Danger, Will Robinson
{
the_condition_variable.wait(lock);
}
With the potential of spurious wakes this is not safe: the
wait might finish even if the condition variable was not
notified. We therefore need the while, which has the
added benefit of allowing multiple consumer threads: we don't need to
worry that another thread might remove the last item from the queue,
since we're checking to see if the queue is empty before
proceeding.
That's the beginner's bug, and one that's easily overcome with a
simple rule: always check your predicate in a loop when
waiting with a condition variable. The more insidious bug
comes from timed_wait().
Timing is everything
condition_variable::wait() has a companion function
that allows the user to specify a time limit on how long they're
willing to wait: condition_variable::timed_wait(). This
function comes as a pair of overloads: one that takes an absolute
time, and one that takes a duration. The absolute time overload will
return once the clock reaches the specified time, whether or not it
was notified. The duration overload will return once the specified
duration has elapsed: if you say to wait for 3 seconds, it will stop
waiting after 3 seconds. The insidious bug comes from the overload
that takes a duration.
Suppose we wanted to add a timed_wait_and_pop()
function to our queue, that allowed the user to specify a duration to
wait. We might be tempted to write it as:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& timeout)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
if(!the_condition_variable.timed_wait(lock,timeout))
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
At first glance this looks fine: we're handling spurious wakes by
looping on the timed_wait() call, and we're passing the
timeout in to that call. Unfortunately, the
timeout is a duration, so every call to
timed_wait() will wait up to the specified amount of
time. If the timeout was 1 second, and the timed_wait()
call woke due to a spurious wake after 0.9 seconds, the next time
round the loop would wait for a further 1 second. In theory this could
continue ad infinitum, completely defeating the purpose of using
timed_wait() in the first place.
The solution is simple: use the absolute time overload instead. By specifying a particular clock time as the timeout, the remaining wait time decreases with each call. This requires that we determine the final timeout prior to the loop:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& wait_duration)
{
boost::system_time const timeout=boost::get_system_time()+wait_duration;
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
if(!the_condition_variable.timed_wait(lock,timeout))
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
Though this solves the problem, it's easy to make the mistake. Thankfully, there is a better way to wait that doesn't suffer from this problem: pass the predicate to the condition variable.
Passing the predicate to the condition variable
Both wait() and timed_wait() come with
additional overloads that allow the user to specify the condition
being waited for as a predicate. These overloads encapsulate the
while loops from the examples above, and ensure that
spurious wakes are correctly handled. All that is required is that the
condition being waited for can be checked by means of a simple
function call or a function object which is passed as an additional
parameter to the wait() or timed_wait()
call.
wait_and_pop() can therefore be written like this:
struct queue_not_empty
{
std::queue<Data>& queue;
queue_not_empty(std::queue<Data>& queue_):
queue(queue_)
{}
bool operator()() const
{
return !queue.empty();
}
};
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
the_condition_variable.wait(lock,queue_not_empty(the_queue));
popped_value=the_queue.front();
the_queue.pop();
}
and timed_wait_and_pop() can be written like this:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& wait_duration)
{
boost::mutex::scoped_lock lock(the_mutex);
if(!the_condition_variable.timed_wait(lock,wait_duration,
queue_not_empty(the_queue)))
return false;
popped_value=the_queue.front();
the_queue.pop();
return true;
}
Note that what we're waiting for is the queue not to be empty — the predicate is the reverse of the condition we would put in the while loop. This will be much easier to specify when compilers implement the C++0x lambda facilities.
Conclusion
Spurious wakes can cause some unfortunate bugs, which are hard to
track down due to the unpredictability of spurious wakes. These
problems can be avoided by ensuring that plain wait()
calls are made in a loop, and the timeout is correctly calculated for
timed_wait() calls. If the predicate can be packaged as a
function or function object, using the predicated overloads of
wait() and timed_wait() avoids all the
problems.
Posted by Anthony Williams
[/ threading /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated (yet again) Implementation of Futures for C++
Friday, 30 May 2008
I have updated my prototype
futures library implementation yet again. This version adds
wait_for_any() and wait_for_all() functions, which can be used either to wait for up to five futures known
at compile time, or a dynamic collection using an iterator range.
jss::unique_future<int> futures[count];
// populate futures
jss::unique_future<int>* const future=
jss::wait_for_any(futures,futures+count);
std::vector<jss::shared_future<int> > vec;
// populate vec
std::vector<jss::shared_future<int> >::iterator const f=
jss::wait_for_any(vec.begin(),vec.end());
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library and some new features of the Boost.Thread library, which are not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing. The documentation for the futures library is available online, but is also included in the zip file.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated (again) Implementation of Futures for C++
Thursday, 15 May 2008
I have updated my prototype futures library implementation again, primarily to add documentation, but also to fix a few minor issues.
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing. The documentation for the futures library is available online, but is also included in the zip file.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated Implementation of Futures for C++
Sunday, 11 May 2008
I have updated my prototype futures library implementation in light of various comments received, and my own thoughts.
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing.
Changes
- I have removed the
try_get/timed_getfunctions, as they can be replaced with a combination ofwait()ortimed_wait()andget(), and they don't work withunique_future<R&>orunique_future<void>. - I've also removed the
move()functions onunique_future. Instead,get()returns an rvalue-reference to allow moving in those types with move support. Yes, if you callget()twice on a movable type then the secondget()returns an empty shell of an object, but I don't really think that's a problem: if you want to callget()multiple times, use ashared_future. I've implemented this with both rvalue-references and the boost.thread move emulation, so you can have aunique_future<boost::thread>if necessary.test_unique_future_for_move_only_udt()in test_futures.cpp shows this in action with a user-defined movable-only typeX. - Finally, I've added a
set_wait_callback()function to bothpromiseandpackaged_task. This allows for lazy-futures which don't actually run the operation to generate the value until the value is needed: no threading required. It also allows for a thread pool to do task stealing if a pool thread waits for a task that's not started yet. The callbacks must be thread-safe as they are potentially called from many waiting threads simultaneously. At the moment, I've specified the callbacks as taking a non-const reference to thepromiseorpackaged_taskfor which they are set, but I'm open to just making them be any callable function, and leaving it up to the user to callbind()to do that.
I've left the wait operations as wait() and timed_wait(), but I've had a suggestion to use
wait()/wait_for()/wait_until(), which I'm actively considering.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Free Implementation of Futures for C++ from N2561
Monday, 05 May 2008
I am happy to announce the release of a prototype futures library for C++ based on N2561. Packaged as a single header file released under the Boost Software License it needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. There is one feature missing, which is the support for alternative allocators. I intend to add such support in due course.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Bug Found in Boost.Thread (with Fix): Flaw in Condition Variable on Windows
Monday, 28 April 2008
There's a bug....
First the bad news: shortly after Boost
1.35.0 was released, a couple of users reported experiencing problems using
boost::condition_variable on Windows: when they used
notify_one()<\code>, sometimes their notifies disappeared, even when they
knew there was a waiting thread.
... and now it's fixed
Next, the good news: I've found and fixed the bug, and committed the fix to
the boost Subversion repository. If you can't update your boost implementation
to trunk, you can download
the new code and replace
boost/thread/win32/condition_variable.hpp from the boost 1.35.0
distribution with the new version.
What was it?
For those of you interested in the details, this bug was in code related to
detecting (and preventing) spurious wakes. When a condition variable was
notified with notify_one(), the implementation was choosing one or
more threads to compete for the notify. One of these would get the notification
and return from wait(). Those that didn't get the notify were
supposed to resume waiting without returning from
wait(). Unfortunately, this left a potential gap where those
threads weren't waiting, so would miss any calls to notify_one()
that occurred before those threads resumed waiting.
The fix was to rewrite the wait/notify mechanism so this gap no longer exists, by changing the way that waiting threads are counted.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: boost, thread, condition variable, windows
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy